
Python Automation Cookbook 3rd edition: now with AI recipes.
Good news everyone! There’s a new edition of the Python Automation Cookbook, now the third edition. Now with a more colourful cover!
As with previous editions, it is aimed at people with knowledge of Python, but you don’t need to be a professional developer. It keeps all the recipes to automate common tasks from previous editions, but it has new content addressing the elephant in the room: AI. So there’s plenty of new exciting stuff like calling AI from your code (both remote and local), MCP servers, AI agents, etc. As well as tips on how to use GenAI tools to write code and help on development throughout the book, which includes proper caveats like security or risks on the usage of AI. The new AI content is over 100 new pages!

It’s written in the cookbook format: a collection of recipes you can read and reference independently, with chapters growing in complexity by combining recipes into bigger tasks. This makes the AI chapters especially powerful, since AI agents and MCP servers can reuse the earlier recipes as building blocks for complex workflows.

That makes five books now, it’s becoming quite a collection! They are all available in Amazon and in the Packt website.
LLMs and Context

Let’s start for something simple. LLMs don’t have memory.
Every time that you make a call to an LLM, you need to provide as an input all the context related to the request. The LLM will pick up this context and produce a result.

But, when using AI tools, for example a chat bot, you see that you have a conversation. And it continues the conversation and references things said before. And that is because the chat bot itself maintains and references the context back and forth. In a naive way, it stores the conversation and sends it whole to the model for each question, making the LLM understand what was discussed before and continue when it left.
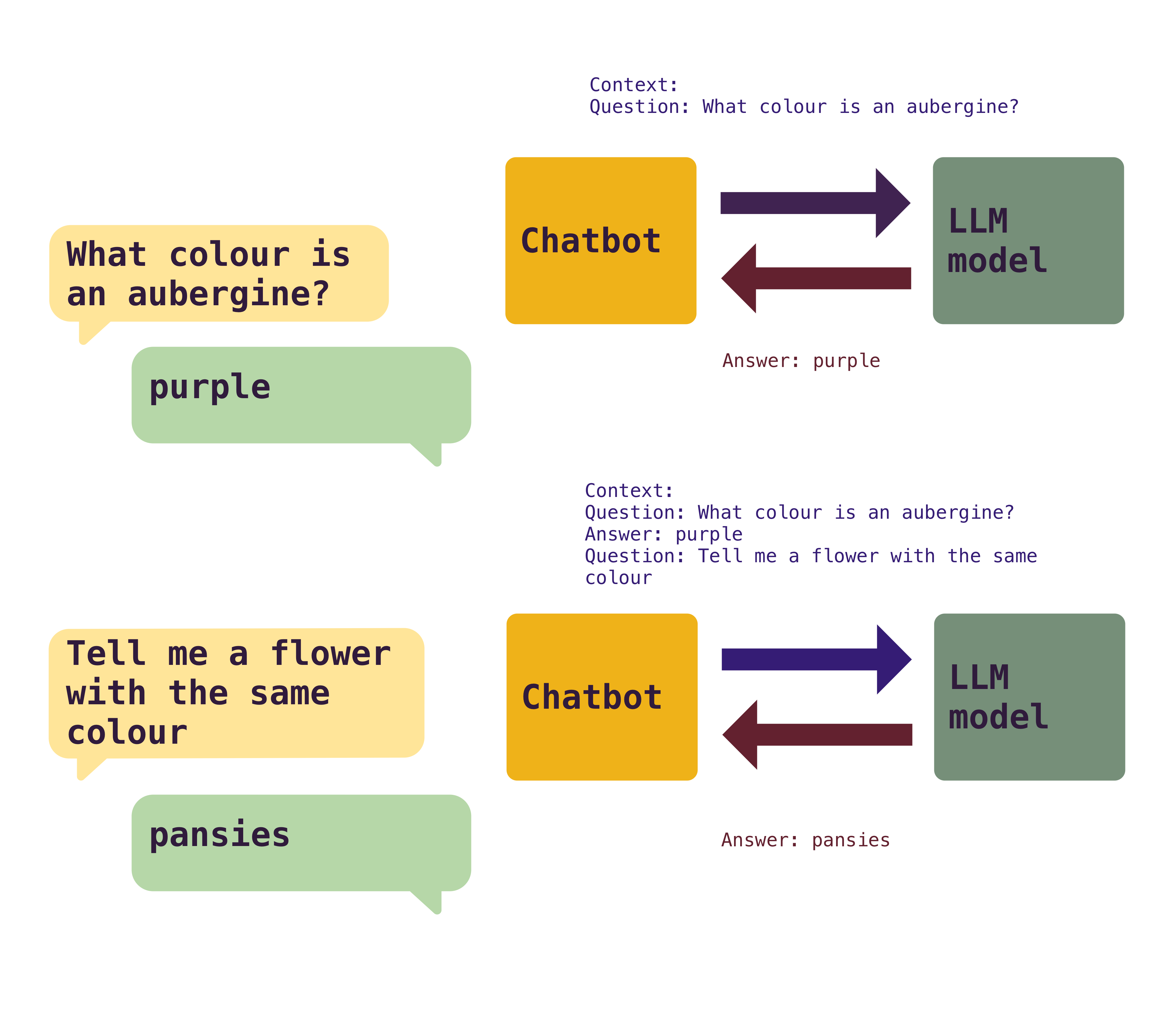
While the chatbot app itself can store the results, there’s a limitation in the part of the LLM on how much context can accept, which limits the length of a conversation. Currently the maximum context window in modern LLMs are around 200K tokens to 1M tokens, depending on model and price.
A token is a part of a word. You can make a round number and think that 1M tokens are about 750K words
While the context appears to be quite high, there are problems where it quickly adds up.
First of all, those numbers are the maximum context window, but not the effective one. Once you start getting over a few thousand words the quality of the responses can start to be affected. The model won’t pay attention to the whole context, but to the start and/or end of it, maybe missing important information in the middle.
Secondly, you can reach the effective limit quite quickly. You’ve probably seen that GenAI tools tend to return a lot of text. A very simple question can return 200 words or more. A complex one way more than that. Going back and forth in a conversation, or even worse, work on a project, can quickly get to 10K+ words faster than you think. Remember that each time you’re adding all the context that was generated before.
Third, your context is not just your questions. Everything that the model needs to know should be included in the context. That can be your preferences (e.g. please return always Python code by default and follow PEP8 conventions). If there are tools (what makes agent capable of producing results), they need to be added to each individual request. And each tool needs to describe what is capable of doing so the model can request its usage.
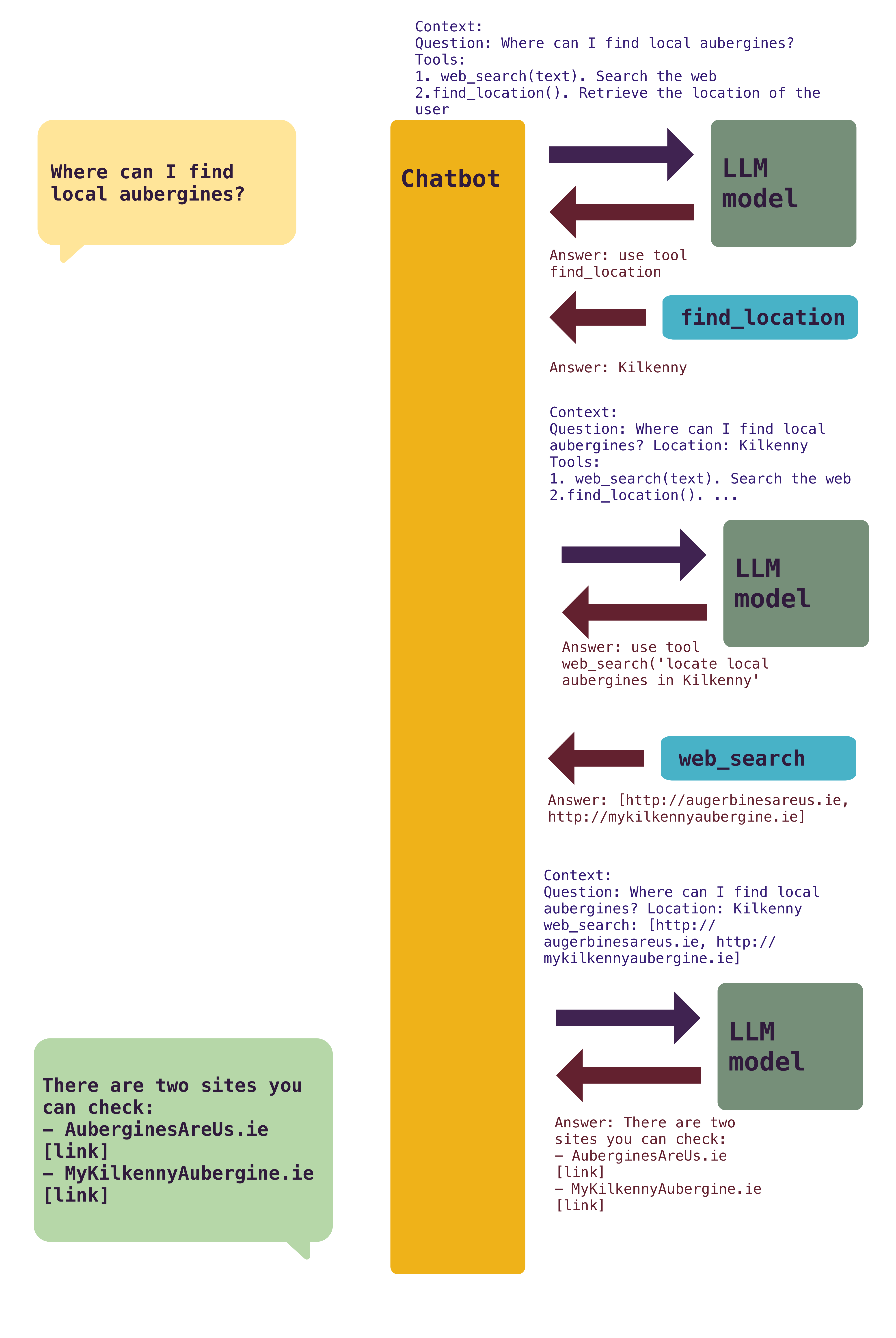
The calls add up quickly. The context grows bigger.
Managing the context becomes an important part of handling any AI tool. There are a few ideas that can be used:
- Compress elements. Reducing the amount of information that’s necessary for describing tools, for example.
- Drops parts of the context. You can explicitly avoid storing parts of the conversation if they are not relevant any more, or including them dynamically.
- Summarise the previous conversation. To keep the whole context, you can ask the LLM model to make a short summary and use that in the newer calls. LLMs are good summarising!
- Chunk the information. Instead of one big call, doing smaller ones with defined task. This is the idea behind doing a plan first (big call) and then following up (run each task independently with a smaller context)
- Avoid including all tools. Instead, dynamically add tools as they are used or requested by the LLM. Tool management is tricky, as each one makes the AI system more capable, but at the same time, consumes important context.
MCPs in particular tend to provide many tools, like 50 per MCP. Having many MCP tools available all the time is not optimal. They quickly occupy the context!
If you develop an agent, which is a loop talking with an LLM, you need to ensure that your context is always healthy for the best results, which makes the management of the context very important.
Managing the context is not only important for getting good results, but also to keep costs under control. Cost is determined by amount of tokens sent to the LLM model. Unless the model is local or in your own controlled hardware, each individual call to the LLM is costing money, and it’s more expensive the more context you add. You can imagine that with complex operations, or agents performing operations for a long time, your bill can grow quickly.
Even if you use a chatbot tool, like ChatGPT, knowing how the context works will help you to better use it and to avoid overwhelm it with too much context.
Agents and Agency

There’s a lot of talk about the capabilities of AI Agents, and a lot of promise on the things that they may be able to achieve. Or not achieve. As well as a lot of excitement, there’s a lot of skepticism, where not direct rejection.
The term of AI Agent is still a bit in flux, but it refers to a program that runs independently with a particular goal and it’s capable of taking actions. The instructions to it are either specific to be done right now (for example: “Go to this codebase and implement this feature I’m describing”) or reacting to the environment (for example: “Monitor this email inbox. If you receive an email from a customer describing a problem, produce actions to create a ticket and notify the right team”.
AI Agents are growing in complexity and capabilities, though is still a field full of experimentation and we probably don’t have a killer app that has been massively adopted. Software development is probably the leading field where AI Agents are used to produce code.
While Agents are capable of somewhat independent action, they do so based on instructions. These instructions are less precise and more abstract than the traditional instructions required for computers, it’s true. But their field of action is still limited. Agents are diligent workers, but with very little initiative. They won’t push back, and they won’t make suggestions.
Ideators and implementers
I think this makes a very fundamental distinction on the kind of person that approaches AI Agents and how they see them, even philosophically. Let’s call them ideators and implementers1.
- Ideators. They like to ideate something, and see it implemented, normally in an experimental way. They like to work alone, or with only a small number of people. They see GenAI as “wow, I don’t need anyone else to do things” and “I can create obedient AI Agents that do exactly what I tell them, and they are very capable!”. Previously, they required implementers to get their ideas into the real world, and they love the possibility of removing that dependency, as finding the right people to work with is difficult, and having to communicate their brilliant ideas is frustrating.
Ideators have a high agency. They are constantly looking for more things that can be done, and producing ideas. They are not worried that they don’t have the capabilities to actually make their ideas possible. Those are details to be worked out later, and probably not by them. - Implementers. They tend to work on more established or complex environments, alongside more people. They have to manage tech debt or legacy systems. They sweat the details, and think that a “brilliant idea” is actually very hard to get successfully implemented, with a ton of small decisions that need to be made. They’ve seen many “brilliant ideas” to be impossible, stupid, or, directly, fraudulent. When dealing with ideators, they are the ones that push back on technical considerations, and ask for clarification many times.
Implementers have a lower agency. They don’t produce as many ideas, and normally follow others. They like to build things, and develop their technique. They don’t like to delegate that much and tend to think on the things that are possible within their area of expertise.

Ideators are extremely hyped on the AI Agents. They are going to be able to produce their ideas quicker, cheaper and without resistance by other humans. They will be able to experiment more. They see a glorious future, AI is the Real Thing™.
Implementers are way more skeptic on the AI Agents. They have seen other hyped technologies before, and many have faded. They are experts in their fields, and probably had a bit of tunnel vision. They’ve tried GenAI, but they see problems and limitations. They are also worried about being replaced, as they are more dependent on having a job and being told what to do.
Seniority
I think that the distinction is, in a big part, a personality one. We all know teenagers that are full of ideas from an early age.
But as you grow in your career, you are sort of forced to move a bit more into the ideator field2. Even if it doesn’t come naturally, the responsibility and ownership will naturally to produce ideas to implement and be more proactive. As well as learn to delegate and don’t be as involved in sweating the details as before.
Going upper in the corporate ladder means going both in higher abstraction and a higher degree of freedom on the specifics, as well in proactivity. You need to come with ideas to implement in your area, big or small. You need to think out-of-the-box, and the instructions will be more and more abstract. The degrees of freedom are not the same in “implement this feature into your module” over “increase the revenue of your division by 20%”.
AI Agents as implementers
Because of the capabilities of AI Agents, is possible that we will end up getting a bit higher into the ideator ladder. We all will need to learn on how to delegate, oversee, and take a higher level approach to think on what’s possible to do, even if we are not able to implement it.
Depending on how capable AI Agents end up being3, and working on software development, which seems like the sector that’s being the most affected, that may be from “a little bit” to “a lot”.
A little bit will mean that GenAI and AI Agents are useful, but they don’t change how we generally work at the moment.
A lot means that the way in which we work is massively affected. In the most extreme scenario, any programmer may end up being forcefully “promoted” to a CEO. To have power over every decision in the system, including sales, as AI will be able to perform all those duties efficiently. This is not a comfortable for many people, including experienced people, as they like certain degree of certainty and make decisions within some frame4.

The shift in responsibility in that case would be huge, and it would be such a big chance that will probably drive many people out of the industry.
At the same time, this promise makes a lot of already CEO-type people really exciting, as they’ll be empowered to a huge levels, without the inconvenience of dealing (and paying!) with a team of people which is difficult to recruit, to manage and to pivot in case different skills are required5.
Reality check
So far, we haven’t seen the kind of massive leverage of AI Agents or even LLMs that correspond to the full AI promise. My personal opinion is that, so far, they are useful tools and they have a real impactful effect in the software development world, so probably cannot be compared with other overhyped technologies like NFTs that ended being mostly pointless.
But at the same time, I find very difficult to believe that they are going to totally reshape the landscape of the industry or put out of work the majority of developers.
My main philosophical aspect of that is that software development is a discovery problem, way more than a construction one. It is not enough to have a general idea, but the idea needs to be challenged, shaped and moulded. Outside of very small projects, it requires the interaction of multiple people. Real people with real agency, that can push back6, add their own ideas and perspectives to the project and can keep abstract ideas in check. Generating a pilot or PoC is one thing. Transforming that into a viable project is another.
But, on the other hand, I’m aware that my instincts are more into the implementer side. Which makes me a bit biased in all of this.
- Both are an oversimplification, obviously. There are two wolves inside everyone… ↩︎
- Probably “true” ideators look for roles that play to their advantage, like sales or being entrepreneurial, from the beginning. A strong ideator may have a bad time following instructions. ↩︎
- This is still under heavy debate, and I personally think is still early to find out ↩︎
- Which can be described as “being told what to do” ↩︎
- It would also probably change a lot of skills required for the CEO-type person themselves, which will create interesting second-order effects. Perhaps your ideas weren’t as great outside of the ecosystem you had them! ↩︎
- Saying “no” is a critically important ability ↩︎
Interacting with GenAI Models

While working with AI is still something relatively new, there seems to be a developing pattern of openness and interconnectivity that’s very interesting. Especially since that seems to go against the latest trends in technology and reminds me of the initial promise of the Web.
We are detaching GenAI Models from the frontend that allows us to interact with them. Let me explain.
When ChatGPT was released, the only way to interact with the model was with through OpenAI application. You wrote in a chatbox in ChatGPT web and receive a response from an OpenAI model. But then shortly we started having more OpenAI models available (chat with GPT-3, GPT-4, o3-mini… so many of them)
But other companies released their own models (Arthropic with Claude, Google with Gemini, Meta with Llama, etc), and at the same time tools enriching the connection with models were developed, mostly IDEs (Cursor, Windsurf, etc). No longer it was a pure chatbox, but these “frontends” managed the information that was provided to the Model itself.

The different tools also became possible to work in Agentic mode, where they interact with the model out of a request/response paradigm, but where the model produces a plan and then calls itself multiple times to proceed with it. All that with interaction from the “frontend” that allows to read/write files, provide settings, etc.
On advance to this, the models can be executed in different ways.
- When you get a paying account with your IDE, you get some allowance to use in models where the IDE company has reached some deal. For example, a Cursor account allows you to execute models like Claude, Gemini Pro and GPT. Extra usage will require you to pay extra. Windsurf works with the same model1.
- You can execute open source models locally using something like Ollama. Your computer may not be capable to run big models, but it’s a possibility!2 No paying in this case, you’re providing the hardware and electricity.
- Directly with API keys from the companies providing the models. E.g. an OpenAI API key for running
o3. This option is available for most premium models in most tools. - With a Cloud provider that allows you to execute models in their servers. This is similar to execute them in your local computer, but in a “rented computer” in the Cloud. For example, AWS Bedrock allows you to execute a big list of models charging you for each of them.
Most projects allow you to pick and choose how do you want to work3. For example, Zed is an open-source code editor that allow you to use all the previous options, including paying them for an account. Aider is a command line tool that is purely open-software and will require you to configure the LLM model to connect to.
All this makes a lot of different combinations. But more importantly, it creates an ecosystem where both elements (frontend and backend) risk being commoditised to certain degree.
Backend Models
It is very easy to change one model for other, even between the same sequence of actions. If there’s a new release (let’s say that Claude 4 is released), swapping to it it’s almost instant. But not only from models of the same company, but from different companies as well. At the moment there’s a lot of activity with new models, and there’s very little moat created that makes OpenAI to retain people if Anthropic releases a new models or vice versa.
Models are extremely expensive to produce and advance. But at the moment there’s a significant group of companies working very hard on them. There’s significant advances done in all of them, and it seems like who’ll win is still unknown.
Even though there is the concept of specialised models (e.g. models for healthcare, laws, etc), they are based on the general models created by companies like OpenAI, Meta or Google. Creating a cutting-edge model is not an easy task, but we live in a world where we have, so far, competition. Of course, the objective of this companies is to be in a “winner takes all” scenario, where they can outpace their competitors and capture all the market, but I’m not that sure that we will get to there.
As a comparison, we can compare it with the situation with search in the early 2000s. Google was much better than the rest of companies like Altavista, Yahoo or Lycos. That was pretty obvious to everyone. Google kept improving, the users moved to use it, and captured all the search market for 25 years4.
But, so far, the difference so far is not completely obvious. Most of the models are quite capable! There can be small differences between models, but there’s no one clear winner so far. OpenAI has the brand recognition so far, which is an important head start, but we are still in early days, and, for example, for programming tasks the one in the lead appears to be Anthropic with their Claude models.
Given on how expensive is to create a model, there’s the chance that some company just goes bankrupt. But, in that case, there’s the chance that they’ll go out in a constructive way and open source their models, in the same way that Netscape created the Mozilla project. If that model is powerful enough, it may provide an alternative to proprietary models, which may drive down the opportunity for the winner to capture the market.5
Another detail here. There’s a lot of chat about the position of Apple in the market. Given how models work, it is entirely possible that they can capitalise a lot on allowing to connect to other models behind the scenes, making their operating systems working effectively as a frontend. This is unlikely6, but possible. On the other hand, in the long term, I think they are capable of reaching their own model and use it exclusively in their products. Just because they are two years late to the party doesn’t mean that they can’t win. They have a huge attachment factor on their iPhones and MacBooks. I think they are in a good position to take advantage of that in the long run.
Frontend Tools
Perhaps there’s a bit more on the frontend front, where people may choose their favourite editor/IDE and become adjusted to them. After all, we historically had our editor wars where people preferred Vim to Emacs or IntelliJ is a viable product even if there are free alternatives. But the main contenders at the moment are VS Code forks, and the Agentic mode makes less important the interface itself, as it is essentially a chat box where you describe the changes that you want to do and the agent itself will do them.
It is very likely that there’ll be open-source alternatives that will cover most of the use cases7, making difficult to really differentiate or create a massive product8. Interestingly, I think there’s a real opportunity into the review part of the process. Make good tools to see the difference with the changes the agent has done, and help summarising and understanding them. So far I don’t think that the work there is stellar, just adequate.
Another element is the integration with MCP servers. MCP is an interface that, in essence, allows an agent to connect to an API and interact the model with them. The API could be a local API or a remote call. Any kind of connection, really. The MCP gives an entry point to the API, including credentials, and a standard way to understand the available APIs for the agent.
For example, you can connect to a local database and create natural language queries that will be translated, through the MCP request to the database. The agent will be able to perform several actions, poking and analysing the MCP to discover their capabilities9.
If there are more than one MCP, the agent will be able to correlate information between the sources. This is an extremely powerful capability. For example, you can use an agent connected to Jira and GitHub and ask the agent to find tickets included in a GitHub release and label them in Jira properly. All this with a natural language request!10
This is now a standard on any tool, and it doesn’t present a differentiation for the frontend tools. It is also likely that many interesting features will be created independently through MCP servers, instead of by the tools’ team.
Summary

All the GenAI are at the moment is incredibly in flux, and it’s very difficult to know what’s going to happen next. I’m guessing this post will get older very soon, but so far my view on this is:
- You can think of GenAI as composed on one frontend (the tool you interact with) and a backend (the model that provides the GenAI capabilities)
- Both ends are pretty combinable. And both risk to be commoditised.
- Backends (models) are extremely expensive to create and to run. There are multiple companies investing ridiculous amounts of money on them at the moment, and there’s no clear moat or indication that we will be in a winner-takes-all scenario.
- Frontends (tools like agents, IDEs, chatboxes, etc) are capable of interacting with the models, and most interesting features may be in interaction with other services through MCPs or other interfaces. There are already capable open-source projects, and agents are moving to be less hands-on.
- Today, working with code, it’s still important to review the generated code. There’s a shift from writing code to reviewing code that may cause a shift in features or tools.
- Agents are capable of connecting and correlating to multiple sources through MCP.
- I use agents that are more thought to operate with code, but I think this is almost ready to move up in the chain to produce local apps more oriented to managers or PMs. Probably there already exist. So far I don’t think that the ChatGPT app allows to connect through MCP natively.
This kind of structures and interoperability reminds me of the early days of the Web. Not sure if it will pan out in the same way, there’s also the possibility that we end up with yet-another massive monopoly/oligarchy. Which was also how the Web ended up being in the end.
- Normally these IDEs will have some free account with a small allowance to allow testing ↩︎
- Plus, you may have a massive computer on your desk ↩︎
- Within a range of options available, of course ↩︎
- There’s one key element, the fact that the search market was free. There was no transition costs from searching from Altavista to Google. With the current models, they all have a cost associated. There could be business deals that make more difficult to move from OpenAI to Claude for companies. I wouldn’t rule this factor as a possibility, in the way that Teams is a very successful “inferior” product over Slack due Microsoft pushing it as part of other deals. ↩︎
- Again, the main difference with the early days of the Internet is that browsers were free. Models are extremely expensive so far to operate. ↩︎
- Apple is a control freak and they don’t seem to like to use a model that is not up to their standards ↩︎
- As we’ve seen, Zed covers most of the features of Cursor, for example. It’s even a bit more flexible in how to set up the backend model to use. ↩︎
- I think it will be totally possible to do a niche product, or even a popular one, but right now it seems that success is more measured in creating N billion dollar products, which is an extremely high bar. ↩︎
- I have to say this feels magical. You just connect the MCP and ask the agent to use it. The agent will start figuring out how to use the API ↩︎
- A use that I found out is to replace the native search in Confluence. Confluence search is, ahem, not great. But if I connect through an agent and ask it to search for something (e.g. “find me the latest updated documentation about X”), it will figure it out producing better results than me searching directly in the web interface. ↩︎
My year in Amazon

Well, it was actually just 11 months, but it makes more sense to round it up.
This happened a bit over two years ago, which in software developer time feels very far away in the past, so I think it makes sense to talk about it.

On 2022 I got an offer to work on Amazon in a sort of unexpected way. They actually contacted me two years before, but at that time I just started a job and didn’t want to move so early. But they came back asking, and I did the interview process without thinking that it would lead to an offer. But here we go in the peak of the software hiring craze, this was just in the aftermath of COVID, and I got an offer.
The process was a bit funny, as the initial offer was to move to Spain. For context, I’m originally from Spain, but I’ve been living in Dublin, Ireland, for the last 15 years now. I’m settled here and I like it. The interest from Amazon was for a team that’s based in Madrid (which is also my home town). In the initial talks with recruiter A I explained that, but I think that was lost in the weeds when recruiter B came along 2 years later.
So the initial offer conversation was a bit like: “We are interested and we are going to help you with the move, etc.”, “Hey, wait a sec, I’m not looking for a move”… So there were some later discussions about that with the hiring manager on different options. The salary offer in Spain was also much lower than the salary I was on at the time, so that was also not really making it interesting.
So, finally, they came with a more interesting offer, hired in Dublin, but working remotely with the team in Madrid. There were some things that weren’t great, like:
- It was using Java, which is a language that I don’t know that well, and that I didn’t like. The “way of doing things properly” in Java is weird for my taste and sort of antithetical to my thinking. I consider myself a Pythonista. But hey, tools are tools.
- I perceived the title to be a step back in my career. I was working as an Architect at the time, and this was to be Senior Engineer (more on that later). I know that titles are a bit silly, but it took me a great deal of time and effort to break that barrier, so it was a bit let down by that.
- I would like to work on smaller environments. Navigating in big companies is not natural to me, and I feel a bit like a number. And I think that I develop good skills to work in small environments, where I can be less specialised and better able to help. Amazon is one of the biggest companies in the world.
On the other hand:
- I’ve never worked before in a FAANG company. I could learn stuff, and worst-case scenario, I’d got it on my CV. There are also good opportunities to move internally to different teams, which could alleviate some of the tech stuff.
- Even if the title is a bit back, I may be able to get a promotion.
- It was a good opportunity in terms of salary and projection.
- I’m interested in performant and scalable systems. Obviously Amazon systems are very big, which was appealing to me.
So I decided to accept the offer. I don’t know, they have been insisting for a couple of years, and I really like that. Also, the worst thing that could happen is that I didn’t like it.
The work
Something that I realised quite quickly was the fact that the title that I was hired to do was, well, lower than I thought. I thought that I’d be hired as a Senior Software Engineer, and I actually was hired as SDE II. Again, titles are a bit silly, but there was a bit of confusion over the process. Anyway, it was all good.
While a lot of people assume that I worked in AWS (Amazon Web Services) I worked on the Books organisation, the shop part of Amazon. This is the oldest part of the company, and it probably is different from other areas, so my experience may be specific for it.

Even if the shop (and Books is already a subset of it) is a smaller part of the whole org it is HUGE. You can feel from day one the sheer size of it, by the amount of things that are automated or done in a way that only makes sense for a massive organisation.
Peculiar culture
Amazonians (the name people working in Amazon gives themselves) are quite proud of their “peculiar”1 ways they work. There are many things that are done in different ways
Leadership principles
The one that’s pretty obvious are the leadership principles. A collection of guidelines that are expected to be followed by everyone. These are a bit different than “values” in other companies as they are a relatively long collection. They are present everywhere2 and there are a lot of idioms within the company reflecting on them. For example, people don’t “research” or “spike”, but “deep dive” instead. It’s quite easy to notice that someone has been in Amazon because they’ll use those idioms casually.
You can be very cynical of some of those principles (really, is Amazon embodying “Strive to be Earth’s Best Employer“?), and the fact that following all at the same time requires imagination (you can easily think on scenarios where “think big” and “frugality” are at odds), but the fact is that they are used as a tool to set expectations and to shape the culture of every Amazonian.
Independent teams
Amazon works with small teams working in a very independent way. The coordination is mostly team-to-team, with not that much hierarchical communication going on.
The result from that is that you are expected to communicate directly with a team with almost no connection with you. And receive requests from teams you’ve never heard of. Without much of interaction from a manager to shape it up or give context.
There’s a lot of semi-automated work for coordination, like requesting access. This was, in fact, a significant part of my work, and worked like this: You update some code that requires access to a particular endpoint of an API which was not access before. You need to request access to that API, to a team that’s very detached from you, through a tool. Then there’s some back and forth with the tool filling the proper information, clarifying why you need access, etc, and finally it gets approved. Then you realised that there’s some other permission that’s blocking your change to be deployed and you start the process with the other team, rinse and repeat.
When the situation escalated from tools to more involved communication3, it could be challenging, as it won’t fit the “standard communication”. As the company is so big, many of the processes need to be adjusted for scale. In my case, the worst case was the communication with another team where there was a disagreement of ownership. Ownership is obviously enforced strictly with tools, but in this case there was a bit of a blind spot, so my team argued that team A owned X (as the tool said) and team A said that we owned it (as it mainly affected us and not their objectives).
I spent a big amount of time with this back and forth, without reaching any particular agreement, and I was requesting my manager to escalate the situation to have a solution. But there was a big reticency to do so, instead expecting the teams to solve it themselves.
Expectations of growth
The whole culture is very very oriented to growth and, more specifically, being promoted. There were a lot of talks, documents, messages in internal chats, where the main objective was, essentially “how to get promoted”. Not everyone played that game, but you could see that a lot of people did, and focused intensively in “promotable stuff” and show up as promotion-worthy stuff.

The company is also incredibly young. Most of developers were much younger than me, in their 20s. To the point that one person on my team, who was around the same age as me, told me that he felt isolated many times, because he never had much relationship with people on the company. They were at different life moments.
Internal tools
All the internal tools, with some exceptions like Outlook, are Amazon-developed ones. They all are very tailor for their use case, and have sometimes strange and unintuitive usages.
The worst case to adapt for me was the specific names and concepts. There was enough people around that had been in Amazon for a while, so when I was trying to ask for something, they wouldn’t recognise the name that I used. For example, it took me literally months to find out where could I check logs from production. I was talking about some tool similar to Kibana, or Loggly, or similar tools that allow full text search. But everyone I talked to showed a baffled expression, saying that there was nothing like the thing that I was describing.
I finally discover that there was an internal tool that does that (I forgot the exact name, but it was an acronym), but it works in a different way, as you couldn’t do full text search, more like adjusting filters. The goal was the same, though, being able to check the production logs. Everyone was using it, but they didn’t understand what I was looking for.
My work was, in many cases, more related to learn how to use all those tools effectively (and navigate finding out how to ask for things so I could be understood) than my ability coding4. There was even some feedback about “please use the right nomenclature for things, because we cannot understand you” in my review.
On-call
As each individual team has a clear field of ownership, and teams are localised in a single place, that means that you need people on-call to support problems. If you think about it, it’s quite insane that a company the size of Amazon, with workers across the globe, requires people to be on-call and wake up in the middle of the night instead of hand over problems to a different time zone, but that was the case.
Our team’s on-call was particularly gruesome. You’ll be on-call for a whole week, and the expectation is that you’ll spend all your time working in on-call tasks. There was a big queue of stuff already when you start your shift. From automated alerts to a lot of other tickets that come from different teams. It was difficult to catch up.
Remember what I said before about team-to-team communication? Well, teams have a way to push for their demands, by creating an on-call ticket for their requests. So that was a very common occurrence. A lot of the tickets that were assigned, sometimes with enough priority to wake you up in the middle of the night were things like migrating code to a new version, or deprecate something. IMO, that’s not on-call stuff, but something to communicate to a manager to get prioritised.
The other aspect that made it difficult was the expectation to take care of everything on your own. Typically, the on-call person is just the first responder and will perform triage. They analyse the situation, but in many cases, the tickets are then distributed across the team. Or prioritised.

That was not the case, the expectation was that you worked on them for the whole week, have a really rough week, and then leave the garbage pile ready to the next one in line5. Every time was a horrible, isolating experience.
I was actually praised because I finished some in-progress tasks after my shift. I had the context and they were mainly to send some emails and get some approvals. They were easier to carry over by a single person than have the context switch.
Let’s get together to read
Amazon culture is very text-oriented. No Powerpoint presentations, more written documents. A pretty weird idea is the fact that there’s no expectation that you’ll need to read something before a meeting about it. Instead, the start of meetings is spend in everyone just reading over the document and adding comments. Until everyone says “I’m done” and then the discussion starts.
In other companies, you’re expected to read a document before the meeting “to not lose time”, but instead, in Amazon, that time is included in the meeting itself, so it’s self contained. You can get your calendar full in meetings that you’ll always have time to read the documents for them.
It’s a very strange situation the first few times, but, if you’re able to get over the weird feeling of “we are loosing time, why are we having a meeting when people are not ready?”, it can be pretty productive. You just allocate the time to read differently, and try to make a shorter meeting because of that.
The change
I was in a strange time in Amazon, because it was at the end of the “COVID hiring craze” and the start of the downturn that followed. Very abruptly it changed from intense hiring to layoffs.
As I said before, the internal culture is very driven to growth and having a career in the company. And, unfortunately also to arrogance or even hubris. This is common in tech in general, but in big companies is easy to end believing that you’re one of the chosen ones. Or at least, that “you’ve made it”. I guess that adding very young people to the mix doesn’t help.
The announcement of the layoffs felt like a disturbance in the Force. The internal channels went on fire about it, and you could hear a lot of broken dreams there. Both for people that were laid off6 as well as people that were scared to be laid off, or that suddenly got a really different idea on when they were.
Morale was greatly impacted.
The next blow was the RTO policy. There was a lot of uncertainty on what that mean, and there was a lot of push back from a lot of people, that went to create pretty thorough reports on why it was the wrong idea. Hey, Amazon is a data-driven company, right? We can present data. It didn’t work.
To me it was also a weird situation. I was working remotely from Dublin, were the whole team was based in Madrid. My manager told me that it didn’t make sense for me to do to the office. But the policy explicitly said that I would have to go three days a week to the Dublin office “to better get the collaboration culture”. Even if that will mean to basically have to Chime7 to the office in Madrid.
Not really for me
All this didn’t help a lot on how happy I was. I didn’t really fit during all my time there, but the prospect didn’t really look that bright moving forward. The first 6 months had been already tough, and I was waiting until the Christmas break to think about whether it was working for me.
Just right before the break, actually it improved, and I felt a bit better, but just coming back it was horrible, starting with a pretty bad on-call week. So I decided to move on.
I think that my personal view on different things didn’t match the strong Amazon culture. Also, my strong points in terms of technologies, knowledge, etc weren’t really useful in the environment. My feeling was that I was on rails, following a very narrow path. I had the impression that the kind of things that I can contribute weren’t useful or welcome, and I like to feel useful.
Probably the team I landed didn’t help, as it’s a difficult team to work in, there’s a lot of legacy code to take care of, challenging from the point of view of the on-call, etc.
There was also managerial stuff that I wasn’t very happy with. I think that a lot of that is, simply, the “Amazon way of doing things”. Also I had an initial manager that was new to the company, and then I changed to another. All of that in less than a year.

So after 11 months I moved to the next role. Where I am way happier that I was in Amazon.
Final thoughts
Ultimately, it was just not a good fit. I got that feeling probably from the start, but I guess that I wanted to give it a try. Too big of a company, and I think it didn’t play out to my strengths as an engineer.
The culture was also not a good fit. Too aggressive, to the point of being cutthroat sometimes. People were more focused on their personal objectives than in teamwork. Plus a lot of arrogance, something that I’m quite sensitive to. I don’t like it.
In terms of what I learn there, it’s interesting, because probably I consolidated more ideas that I had been exposed before. I worked in Demonware, an online services company that runs services for Activision (the biggest game was Call of Duty). There I was exposed to how to work on very big systems. It’s probably not as big as Amazon shop (nothing is), but the gap is not massive. A lot of ideas are very similar, so they were good to validate with a second, totally unrelated application. The architecture of the system was also designed to allow many developers to work without being able to bring the whole thing down, but at the same time it felt very constraining.
So finally at least I was able to confirm that very big companies are not for me.
- Yes, that’s the way to refer to it internally. ↩︎
- They are prominently displayed in different walls in all offices, for example. But also referenced in documents, surveys, reviews, etc ↩︎
- There are also “office hours”, available slots for a team to give support to other teams. They are great to ask information, but not so much to get certain team to do something. Every team is very protective of their time. ↩︎
- I actually didn’t write that much code in my time there. ↩︎
- Hopefully, a slightly smaller garbage pile ↩︎
- Fortunately, my team was not affected ↩︎
- Chime is the internal tool equivalent to Zoom. Didn’t I say that most of tools are Amazon-developed? ↩︎
Adventures in Vibe Coding

Recently, I’ve been playing around with GenAI tools. Yes, I know I’m late at this point, but these days coding is not as big a part of my day-to-day as it used to (though I still do it regularly), and I have never been too interested in autocomplete tools, which has been the way most of the GenAI for programming has been labelled.
The integration also with my regular workflow is not as straightforward. Most of the tools are more based on an IDE, most of what I’ve seen has been mainly derivatives of VS Code, probably the most popular IDE at the moment. But, as I’ve discussed in this blog before, I’m firmly into the “Vim text editor / Command line as IDE” kind of flow. there are things there, but not as extensive as the ones for the IDEs. Of course, part of that is my language of choice, Python, where the dynamic typing nature of it makes less of a requisite the autocomplete and other niceties of an IDE than for other options like C or Java.
Anyway, given that the basic interaction with GenAI models is text, it’s actually quite flexible, and there’s a lot of activity into integrating them into different workflows.
Which brings us back to the Agentic flow, which is the one that’s getting most interest at the moment. In essence, instead of having a “super powerful autocomplete”, that integrates with your writing code flow and present suggestions, it works more as an extra prompt where you ask the agent to generate or change your code in certain ways.
This is, as far as I know, not available with an integration of my workflow1, but more with certain new IDEs like Cursor or Windsurf. I tried both and they both look to me quite similar in the way they operate. They present a screen with your code and a prompt where you can enter questions or actions. The prompt, which acts as a chat window, will show the response from the agent, and any change on the code will be labelled so it can be reviewed and approved.
For example, starting a script from the start, you can request something like:
Create a script that analyses a git repo, and presents a graph showing the amount of commits between tags, and the number of commits that contain the word “merge” in their commit messages
The agent will go and write for you a pretty capable script following your requirements, which then you can review and execute. You can iterate through it, making more comments as it generates the code. For example, you may need to ask for adding a requirements.txt file, as it will tend to add required libraries. For example, matplotlib if you ask for a graph.

The interesting part of all of this is the fact that the agent will produce a lot of text describing the actions and what is doing, to you to verify what’s doing.
Tools
I’ve been trying mostly Cursor. I’ve also taken a look to Windsurf, but they operate in a similar way. They appear based on VS Code, with some add ons to integrate the AI tools.
The operation on both in Agentic mode is very similar. You describe the action in the chat window, and the agent presents the changes, labelled as such, and a response with the changes and options that it’s produced.
In both cases, you are talking with someone and overseeing the results.
Models
With all the hype about different modes, I think that, at certain level, they are on the way to be somehow irrelevant. Sure, there’s differences, and the most powerful models are actually pretty expensive and capable.
But they are on their way to be a commodity to a certain degree. As all of them are improving and the tools are presenting a detached version of them, I think very soon they’ll become something in the background that doesn’t have a big impact. In a similar fashion than using a particular CPU can produce better results, but most people are not worried about it. They just have one that is good enough for their usage, and don’t ever think about it.
I think that models, outside of very specific use cases, are going to be quite difficult to differentiate, with probably a bunch of them being “good enough” for most use cases.
It’s also very difficult to test the exact same action in different models to see the differences. It’s more “this appears to be producing better results”. And anyway you notice is that 6 months ago they were less capable than they are now.
Both Cursor and Windsurf allow to configure the models to use. Some can be quite expensive!
Three kinds of software
I tend to write three kinds of differentiated code, with different expectations and usages2
- One off code. This is code generated for a very specific case, that will run only once. Could be changing the format of a file into another, solving a particular query of some sort, etc. The important part is the result of the task, and not much the code that generates it, as it’s not going to be run again.
- A recurring internal task. These tasks are run normally manually, and with some ad-hoc purpose. Could be to prepare some report, let’s say semi-regular growth info. They evolve over time, but some parameter is typically required. Because is being adjusted from time to time and run in different situations, maintainability is more important than before. But given the manual nature of them, there’s still no need for enforcing “best practices”. Convenience trumps. When this gets out of hand, this code evolves and becomes so complex and critical that everyone hates it.
- Production code. This code has, since the beginning, the purpose to run many times, with little to no supervision, and should conform to a high bar to ensure that it doesn’t break (and/or can recover from failure), is performant, maintainable, readable, compliant, and multiple people can check it out and expand it. Testing is important, as are metrics, logs, etc. And the fit within the architecture of the system, both the software one and the organisational. This is the “software engineering” part over the “coding”
While software developers will always talk about the importance of standards, the fact is that these three levels of code can get away with a very different coding approach. Trying to be super strict with something at level 1 is missing the point.
Code can, and sometimes do, move up in this scale. A task that started as a “there could be something here” (level 1) to “let’s do a small POC” (level 2) to “let’s ship it” (level 3). But it doesn’t go down on the scale. The level of effort grows exponentially with each level, though. It is not too difficult to move code from level 1 to level 2, but moving it from level 2 to 3 is a lot. This is the kind of process that takes a company to scale from a small pilot to a full grown operation. You can probably argue that there’s an intermediate 2.5 level which is typical of new companies, where the product is still young, the codebase is small and moving fast is more critical than stability, but things are a bit planned. If the company is successful, all that “tech debt” will have to be addressed and move to proper level 3.
My experience is that Agentic code development excels at levels 1 and 2. As we have seen above, it is very easy to describe a particular problem and “guide” the agent to a solution that it’s good enough. It allows to generate POC and initial code super quick and easy. It gets good defaults and can implement something that’s useful very fast.
But moving to the next level is more difficult. It can help on productionise code, adding logs, metrics, etc. But operating an existing code base that works is not trivial, and requires more attention to the different actions that are created. It can help, though, and can suggest interesting code that can be integrated, with the right supervision. But in level 3 purely the “write code” part is not the only thing. Standards are important, but relationship with many other moving parts, and that includes teams, permissions, etc, is critical.
Testing
The best way to work on those situations is actually by using TDD. Define the tests that the code should pass, and then generate backwards the code that should fulfil the use cases.
I’ve seen a lot of recommendations of using Gen AI to generate tests, but other than helping with the boilerplate, I don’t think that’s the right approach. It should be the other way around. Generate the test cases yourself, paying attention to what you’re trying to do, and then ask the Agent to change the code to accommodate them.
Testing your code is an activity that should be approached with the right mindset. The idea is that you double-check that the code is performing as it should, doing what is supposed to do (and not doing what is not supposed to do). Certain detachment is useful, because it’s very easy to fall into the trap of creating tests that verify what the code is doing, and not what it should do. The key element in TDD (write tests before writing the code) is to increase this detachment and force the developer to define the result before the operation.
For level 3 code, if we want to use Agentic mode, I think is important to achieve this decoupling from tests and code. And, for that, the easiest is to create the tests independently. GenAI can still help with the boilerplate! But set the test cases independently.
Experiences
In more specific cases where I’ve tried to use it, and experiences, I have been using Agentic mode, among other usages, to do these actions:
Creating a few scripts between level 1 and 2 for creating graphs and compiling data for analysis and presentations
This was incredibly productive and positive. I wanted to compile some statistics about a couple of git repos to show evolution of the development process. I was able to create scripts that were pretty capable very fast, and presenting data. There were some problems with how the data was presented, and some stuff had to be adjusted, but if I had written these scripts myself, I would have the same problems. In general it was a big saving of time.
Update the version for ffind
I developed and maintain a command line tool to search files by name called ffind. I use it day-to-day. It is pretty stable by now, and I try to keep it up-to-date with new versions of Python, etc. It has a good suit of tests, CI and good coverage. So I thought “why don’t I try to update it using an Agent? Normally is just changing a few number in the files and push the new version”. So I did.
The process was a bit more complicated than anticipated, because the usage of setup.py script has been deprecated in the latest version of Python. So I had to change how the project was built and installed. The Agent made the change to hatch,. which is a tool to help with the build of the package and installation. This was not without its difficulties.
The Agent tended to hallucinate quite often, presenting methods and calls that were not real, and mixing the interface for hatch. Some hallucinations were easy to spot, for example, it tended to change my name on the package, for some reason, to another Spanish-sounding name. I’m talking about the copyright in the license and things like that. That was strange.
More difficult to know was the non existing methods on the hatching module, and the changes that left dead code or mixed something. Given that I have a pretty good test coverage, it was easy to detect, but it was pretty disconcerting. Another interesting detail was that the Agent didn’t really learn. If I told it “you’re changing my name there”, it will apologise, but three questions later it will try to do the same thing.
The process was, though, relatively quick. It was quicker than if I had done it on my own. I would have fixed it, but probably would take me a bit longer.
Commoditisation
A surprising outcome to me is probably that I can clearly see that AI is pretty much in the way to be commoditised. The different IDEs are not that different, and the abstractions and opinions they pose are not that different. Working through code in an Agentic mode is, at is raw level, having a conversation and reviewing results3. There is no secret sauce or moat other than “Model X is better”.
But the differences between the models are also fuzzy, and difficult to address. There are a bunch of very capable models already, and they don’t change how you interact with them. You can start using another model without changing anything on your interaction. Just configure to use model M+1. Perhaps there’s the possibility of specialised models (e.g. a model that’s tailored to generate Java code, or embedded code), but so far the industry seems to go for generic coding models. And using one model or another is just a matter of changing a config file. It’s not as changing a programming language or even a text editor, which have more opinionated statements. It’s just using a chat box. I wonder if, at some point, models will have their own opinions as a way of differentiating them.

In an essence, is like going back to early 2000s, but instead of having to choose between Altavista and Google, you have three different Googles that produce similar results and evolve very quickly. The window of opportunity for a winner takes all is not likely there.
Embracing the vibes
The interesting part, though, is the fact that it all devolves into vibe coding very quickly. This term is not 100% clear at the moment, as sometimes it seems to mean just work with an Agent. But what I really mean is that you start delegating a lot on the Agent. You are just interested in the end result, and less in the underlying code that generates it.
Yeah, whatever, just show me the result
And I think that’s both the incredibly powerful potential of the tool as well as the danger inherent to it. For code in levels 1 and 2, really the output is all you need. The process to get there is less important.
But for level 3, what the code is doing becomes critical. It needs to be analysed critically, in the same way that you’ll do with a coworker. But we all know that good, thorough code reviews are difficult. There’s a level of implicit trust on your coworkers that allow for a quick “👍 LGTM”, especially for long PRs, that is not ideal here. This can be a big difference in work, from focusing on writing code to reviewing code, from very early in one’s career.

This is probably a key element why a lot of business people and leadership are so hyped about it. They can use it for the kind of tasks that they perform! Really creating a new website from scratch is super easy, or produce a POC about something to test it out. But I think that scale them into a “real business”, where performance, stability and consistency is critical can present a challenge, at least for now. A great deal of actions in a stabilised company are not about adding more code, but about first finding out subtle things that are going on, define and align features with existing code, which is not trivial to do. Not that GenAI cannot help there, but it’s less magical. There’s no silver bullet!
The other caveat is that, as a developer that likes their job, it can suck the joy out of it. I like to write code and to think about it. It’s true that you can generate code faster, but at the same time, it’s sort of the most enjoyable part of my day-to-day. I’d prefer if it was able to handle my JIRA tickets and status report meetings instead, to be honest. I hope that we start working on tools more focused on those tasks, which is really the thing that I’d prefer to automate.
Writing well is thinking well
At a fundamental level, writing is structure thoughts around ideas and confronting them with the real world, even if it’s just to be self-sustaining. While proof-checking and helping with grammar, etc is greatly advantageous (and even more so as a non-native English speaker), relaying too much into generated code can produce laziness of thought. Some subtle details are discovered while you are thinking hard about the details. It’s not unusual to realise a bug by talking with someone that wrote the code about some condition and then connecting the dots. Generating the code automatically removes this intimate, instintual knowledge of the code.
- I’m putting this on the Internet, so I expect a lot of people telling me how incredibly wrong I am ↩︎
- Please don’t take these levels too seriously. They are very broad ways to talk, but different code bases have different expectations and practices. ↩︎
- And I have hope for having a more “command line centric Agentic mode” that I can integrate more into my workflow. ↩︎
Insights from ShipItCon 2024

Another year, another ShipItCon!
I’ve talked already on the previous instances of the conference. To keep things short, it’s an annual conference based in Dublin that works around the idea of releasing software.
Because it’s very open-ended topic that can be approached from lots of angles, and it’s something different from the more stereotypical “conference around a technology”, the talks are quite varied. The organisation always finds good speakers that talk about interesting concepts, from very different points of view, making it quite broad in scope. It’s full of, as the MC CK will say: “golden nuggets”
There’s always a general idea to shape the discussion around, and this year it was flow. But how that’s approached depends very much on the speaker, as we will see.

I always take lots of notes and reflect on the ideas that were presented.
Talks and Notes
DevOps Topologies 10 years on: what have we learned about silos, collaboration, and flow? by Matthew Skelton
Matthew Skelton, one of the authors of the book Team Topologies reflected over the concepts introduced on the book a decade ago. The idea of the DevOps topologies (which I didn’t know before attending to the talk) is quite interesting, describing different good and bad patterns (sorry, the word “anti-pattern” is quite strange to me) on how DevOps teams can work in relation to both Dev and Ops.
A very interesting point on idea of the topologies is the understanding that they are dynamic. Team structure is not a fixed thing, but it’s always a conversation where projects, initiatives and changes are always happening.
He talked about the concept of decoupling, and how that can help achieving high flow of value and improved efficiency. Decoupling is the opposed to coordination, allowing teams to work independently. But to achieve this, teams may need to change. Decoupling is actually very complicated, and it can be very hard to implement. One interesting tip was that making teams responsible for costs helps define boundaries, as they’ll need to impose limits on what cost is attributed to what team.
But decoupling is not the only thing that is required. Aligned independent teams is more difficult, and risk making them silos. As a counter-balance, it requires knowledge diffusion that flows from the teams to share lessons learn, create a cohesive culture and be sure that everyone is moving in the same direction in the organisation. Some of the elements that can help in that regard are things like internal conferences, lunch & learn, etc…
Organisation, Flow, and Architecture by Sam Newman
This was a very funny talk talking against ideas coming from Taylorism based on assembly lines of having “smart managers” telling what to do and “dumb workers” doing it. He introduced the idea of how hand-offs (tasks moving from one team to another) are terrible for flow and productivity, require a big deal of coordination and meetings. Team specialisation in software (e.g. a backend team, a database team, etc) tends to emphasise the necessity for handoffs of tasks from team to team.

He went back to the main ideas on the foundation of Agile (not on Agile as a consultant-driven idea), especially in relationship on self-organising, stable teams. Short term teams, in particular, are terrible as they are driven from outside (the objective that creates such short term team) and have all the incentives to create a big short-term mess of tech debt.
Data Driven Decisions to Improve Testing Flows by Heather Reid
The speaker described with examples different moments were capturing the right data was key to understand what was happening in production and make better decisions. She went over the concept of risk, in particular as related to testing, and how solid data can help understanding and limiting that risk to make more informed decisions that takes the right amount of risk.
Good testing is about finding problems
She also described how data should be used on day to day routine, not just when things are on fire, and critically analyse when more data is required, to collect it when possible.
She also went over some ideas for test teams, like close old bugs that are not critical (reopening them if they are important again) as a way to eliminate noise and improve morale. And also about how users doesn’t behave as we imagine and having solid data collected will showcase what they are actually doing, so changes can be addressed based on reality and not perceived problems.
Flow belongs in production by Charity Majors
She developed the idea that the main job for managers and leads is to create quick feedback loops and how performance is different from good engineering.
The main goal for that is to ship code swiftly and safely, which in itself is not purely a technical task, but a sociotechnical system (involving both people and technology interacting). A counterproductive realisation is that, when related to software, speed actually tend to lead to safety.
Important modern engineering practices are all about feedback loops, like engineers owning code in production, test in production, CD, feature flags or observability-driven deployment.
She spend a significant amount of time talking about observability and how “Observability 2.0”, with rich structured data flowing and clear single point of truth was going to enable better understanding on the behaviour of the system, and award curious developers with knowledge.
Establishing a culture of Observability at Phorest by Paweł Mason and Paul Daily
The speakers talked about the adoption in Phorest of observability tools (in this case, Honeycomb), and how , as they were gaining adoption, they were using the feedback that it provided as a way of improving their understanding of the system and reinforce it by better instrumenting the code. It was interesting to hear that, while the tool itself was not the total answer, it helped to shape the interaction to improve the practices.
As they introduced SLO (Service-Level Objective) as contracts between product and engineering, they worked with the idea of the Error Budget, the understanding that, based on an agreed SLO, you have some margin for error and how that can be monitored and used to control risk.
Go with the Flow by Vessy Tasheva
Vessy talked about the psychological aspects of Flow and how it’s an interaction between the internal individual forces of exploration and play (as opposed to reaction) and an external environment that provides a needed safety and trust to allow it (as opposed to fear).

She discussed the concept of “holding environment” (created by Winncott, a paediatrician in relation to mother-child bond) as one that’s both safe and uncomfortable enough to drive growth.
Flow-etry in Motion: Navigating Cascades of Threat Data by Claire Burns
Clarie commented on a (failed) migration of a system to Kubernetes and GCP. After analysis and some work, it was decided that it was not the right fit, and it pivoted from there.
Nonetheless, this project helped learning tools (like Kotlin, in this case), stretched the team to learn new stuff, even if ultimately was not the right fit for the project. Perhaps in the future? The main takeways, in her opinion, were that you need to set the ego aside, understand that no single tool work for every project or anyone and use the right tool for your use.
Panel discussion moderated by Damien Marshall, with Laura Nolan, Charity Majors, Ronan O’Dualing and Patrick Kua
The always interesting open discussion about the main topic of the conference, flow. I took some notes of ideas discussed, in an scatered format
- Losing hyper focus when moving to a managerial position or more senior positions, in general
- Working with more ambiguous tasks
- Difficult to get flow as Senior or Principal, as dealing with longer feedback loops
- Protect your time, own your calendar, say no to things. Try to divide tasks into smaller blocks that can be finished in half a day, to set up realistic progress.
- Avoid only providing feedback and reviewing, as creating is inherently more difficult than questioning, and that can make to loose touch and motivation
- A reference to this article by Will Larson: Migrations, the sole escalable fix to tech debt. When migrations are finished, they should be properly celebrated.
- Culture, which should allow for healthy disagreement. Companies should not be fun, but healthy.
- Doing hard things brings up feelings
- The concept of “escaped interaction”, which means to perform a manual task outside of the process or tool, and requires context.
Harnessing Developer Insights to maximise flow by Mihai Paun and Alma Tarfa
They talked about two extremes, presenting two hypothetical examples in two sides of a spectrum to talk about how organisations tend to homeostasis, to be resistant to change and carry big inertia.
Some of the changes need to be driven slowly, but consistently, as small habits compound over time. They also talked how very important things are not quantifiable.

They described leaders as gardeners, not mechanics, as they need to nurture the proper environment and correct things constantly, not design something perfect and follow a template.
They talked about self-reflect as teams, and to ask and enable developers. As well as asking, what small thing I can commit to the next week (not a longer period of time) that will positively impact your environment?
From MLOps to AI systems by Jim Dowling
This talk was more technical and related to AI systems challenges and I personally found it a bit challenging to follow, as it was also quite quick. I learn some stuff that I didn’t know about production related challenges.
Jim talked about the challenges of bringing Machine Learning and AI systems into production. 48% of AI systems fail to get to a production environment.
There are big issues in the way that ML systems need to be architecture and the difference of skills and competences that are required in different areas, and how those areas interact to each other.
Finding personal flow by Patrick Kua
This talk was structured around three projects, in chronological order. The first one was about working on a side project to create a continuous integration system by setting a Perl script gluing code. This was more about individual flow, learning and ownership.
The second was to rework an email templating system with a team, on a tight deadline. This was more about playing around over team strengths, using Acceptance test-driven development (ATDD) and receive a design already lied out by an architect.
The third project was about a bigger project and the impact in trying to handle it all by a single person, and how that got to a lot of stress and required to stop for a few days. Once back, the responsibility was shared and people were made “feature leads” to get ownership of specific features, which lead to more engagement and less single point of decission.
He ended up commenting that flow is uneven, and you cannot wait for flow to find you. Also about flow as an spot between boredom and stress where you can grow.
Final thoughts
As it happened in previous years, I’m impressed with the quality of the talks and I was very happy to attend the conference. This year they sold out all the tickets, which is a sign that it’s been successful. Over the years I’ve been more and more convinced that the release is the heartbeat of a software company, and I always get back from the conference with ideas that I can try to apply in my work. In some cases a couple of years later.
So totally recommend to take a look if the release of software is something you’re interested in.
Notes about ShipItCon 2023
It’s this time of the year again, and another ShipItCon review is due!
I’ve talked about the previous instances of this conference, which happens in Dublin, roughly once a year (though the pandemic years it did not happened), and I think is a quite interesting conference, especially as it revolves more about the concept of Software Delivery, in a broad sense. That makes for very different talks, from quite technical ones to other focused more on team work or high concepts.
Perhaps because I’m getting older, I appreciate that kind of “high-level” thinking, instead of the usual tech talks diving deep into some core nerdy tech. It’s difficult to do properly, but when it resonates, it does quite heavily.
The conference
The conference itself is run in The Round Room. This is a historical place in Dublin, which actually served as the place for the first Dáil Éirann (Assembly of Ireland) to meet.
The round space and the fact that you sit on round tables gives some “Awards” or “political fundraising” vibes, more than the classical impersonal hotel in most tech conferences. The place is quite full of character, and it allows for the sponsors to be located in the same room, instead on the hall.
There are some breaks to allow people to mingle and chat, but the agenda is quite packed. As well as an after party, which I didn’t attend because I had stuff to do.
As in last year’s, CK (Ntsoaki Phakoe) acted as MC, introducing the different guests and making it flow. It’s unconventional, but it helps to keep momentum and helps making everything more consistent.
The topic for this year was the unknown, and, in particular, the unknown unknowns.
Talks and notes
Some ideas I took from all the different talks
Keynote by Norah Patten
Things started quite high with Dr Patten, which is set to be the first Irish astronaut. She described her path, from her childhood in the West of Ireland, where she was fascinated with space, especially after she visited NASA. She studied aeronautics engineering in Limerick and later in the International Space University in Strasbourg, where she got exposed to international cooperation, key for space exploration.
She got involved into experiments in microgravity and participated in Project Possum, a program to train scientists into microgravity and spaceflight. One of the highlights of the talk was to see videos of her absolutely ecstatic when reaching microgravity in some of the flights, where you can see that she really belongs out of Earths gravity.
Some interesting details she went over were the training on space suit, where the suit is pressurised and it has a lot of noise inside, as well as all her work inspiring other people, both to help experiments to run in microgravity environments, and well as a general role model.
What’s slowing your team by Laura Tacho
Laura talked about the different ways of measuring the performance of teams, and how there are now some metrics in the form of DORA or SPACE. But, she argued, those are related more to known unknowns than to unknowns, following the topic of the conference.
All data is data
that include things like opinions or 1:1 conversations
She studied recently a lot of trams and she found common problems in most cases, in three areas:
- Projects:
- Too much work in progress
- Lack of prioritisation
- Process:
- Slow feedback, both from people (like feedback on PRs) and from machines (like time for the CI pipeline to run)
- Not enough focus time, like time free of interruptions
- People:
- Unclear expectations, which can lead to a loop of micromanaging, as tasks are defined too broad, which leads to not complete the expected work, then correct by micromanaging, and start from there again the loop.
All of the elements of the list are probably not surprising to anyone with some experience. The problem is not that much to recognise these problem than act against them effectively.
To continue with the work, she recommended DevEx. Interestingly, she also recommended the book Accelerate, which was commented in a couple more occasions during the day. It’s a great book and I also recommend it.
Large Language Models limitations by Mihai Criveti
This feel over the more “technical side” of the talks, and, unfortunately, got some tech problems in the presentation. It discussed some of the problems with LLMs and some ways of mitigating them.
The interesting bits that I got there were that LLMs are very very slow (in Mihai’s words, hundreds of times slower than a 56K baud modem from 1995), and expensive. Expensive to operate, as being so slow requires a lot of hardware (around 20K in a cloud provider) for “someone” writing at a very slow pace, as we’ve seen. But prohibitively expensive to train with new data.
An LLM model requires first a training phase, where it learns from a corpus of data. This is insanely expensive. And then an operation phase, where it uses it to answer a prompt. But LLMs doesn’t have memory, they only can generate information from the training. there are some tricks to “fake” having memory, like adding the previous questions and answers to the prompt. But prompt has a small limit, and the whole amount that it can generate is around 7 pages of texts, and it gets weirder the more it has to generate. Which makes difficult to create applications where either it has to understand specific information (as it needs to be trained for that) or it requires a relatively big input or output.
Another interesting note is that LLMs work only with text, so anything that needs to interact with them needs to be transformed into pure text, which makes difficult to work with things like tables on a PDF, for example.
How to make your automation a better team player by Laura Nolan
Laura already gave talks in previous years and they have always been interesting. She discussed some concepts coming back from the 80s in terms of operators (people operating systems, particularly in production environments) and automated systems and how the theory of the JCS (Joint Cognitive Systems) emerged.
This theory is based in the idea that both automated systems and operators cooperate in complex ways and influence each other. For example, having an automated alarm can actually make a human operator to relax and not perform checks in the same way, even if the alarm is low quality.
Looking through that lens, there are two antipatterns that she commented:
- Automation surprise, the idea that automation can produce unexpected results or run amok. Some ideas to avoid these problems are:
- Avoid scattered autonomous processing, like distributed cronjobs (she gave a great advice avoid independent automatic OS updates). Instead, treat them as a proper maintained service.
- Be as predictable as possible
- Clearly display intended actions, including through status pages or logs
- Allow operators to stop, resume or cancel actions to avoid further problems.
- “Clippy for prod” or very specific recommendations and “auto-pilot” for operations.
- “It looks like you want to reconfigure the production cluster, may I suggest you how?”.
- Very specific recommendations can misdirect if they are wrong, so be careful.
- Provide ways of understanding system behaviour is often more useful. For example, “Hard drive full, here are the biggest files” can lead to more insight than “Hard drive full, clean logs? Yes|No”
Finally, she talked about two types of tools under JCS, amplifiers and prosthetics. Amplifiers are tools that allow to do more for the operator, normally in a repeated way. For example, a tool like Fabric, which can deploy into multiple hosts and execute some commands on them. It doesn’t change the nature of the commands, which are still quite understandable. If it fails in one host, but not others, I can probably understand why.
In the other hand, prosthetics are tools that totally replace the abstractions. On one way, they allow to perform things that are totally impossible otherwise. But, at the same time, makes use totally dependent on the underlying automation. Here there are things like the AWS console. What’s going on inside? Who knows. If I try to create 10 EC2 servers and one fails, I can only guess.
Laura suggested building amplifiers when possible and to not hide the complexities. I think is a bit analogue to the “leaky abstractions” problem. At the same time, in my mind I relate it to my way to look at the cloud, where, in general, I prefer to use “understandable” blocks as much as possible (instances, databases, other storage, etc) and build on top of that, over using complex “high level rich services”. I may write at some point a longer post about this.
Granting developer autonomy while establishing secure foundations by Ciaran Carragher
Ciaran gave a talk focused in security, and how it should be looked to the lens of allowing developers their autonomy while establishing secure paths and try to simplify security. Or, better describe, make the easy path secure.
Looking at different perspectives, there are some opposing views. Developers want to have immediate access when needed, to build and test without interrupting their flows, and to be able to perform tasks when they evolve. At the same time, from the point of view of security, there are requirements in terms of minimising risks, follow regulation, and ensure that security is key. So there’s a dilemma in allowing that teams can remain performant and innovative, while the system is secure and, especially, the customer data is protected.
He went to describe several examples on his experience, and some actions taken. Most of that was quite AWS specific, which seemed like his area of expertise. His main recommendations were to find a balance, trying to not bother developers too much provide the means to be secure; and engage with experts (in his case, talked about AWS, but I’m generalising it a bit) as early as possible to be sure to not do silly mistakes. Security is hard!
Unpeeling the onion of uncertainty by Rob Meany
Rob described how our developer careers are filled with failures. I think that everyone can relate. Even the most successful software companies release way too many things (products, features) that don’t really get any traction. We are talking that most software release is a disappointment, even in the best of circumstances.
So we need to, first embrace this fallibility and be prepared to not be too attached. And, second, try to fail faster, so we can confront our releases with reality as soon and as often as possible.
We spend too much time building the “wrong” solution in the “right” way
He has this idea of the “onion of uncertainty” which in its outside is more uncertain (more related to the real world and business) and it becomes more technical and manageable as we get inside. So a new feature will need to start out, go inside, and then get back again out to be confronted. He created a list of principles to try to navigate it

I think it follows quite closely the principles of Agile. But it was very well constructed and thoughtful talk and he gave quite concrete examples. It was one of my favourite talks on the conference.
Just because you didn’t think of it doesn’t make it an edge case by Jamie Danielson
Following on the unknown topic, Jamie talked how there are a lot of events in a production system that you cannot really foresee, and that requires a proper observability structure to be able to address and detect. She followed a real example and gave a few recommendations:
- Instrument your code
- Use feature flags to allow quick enable and disable of new code
- Iterate and improve in fast loops: reproduce, fix, rinse and repeat
Panel discussion moderated by Damien Marshall, with Laura Nolan, João Rosa, Diren Akko and Siún Bodley
The classical panel discussion about the topic of the conference: the unknown. some of my notes:
- Learning from failures
- Importance of documentation
- People as single points of success
- Team’s autonomy is key to reduce risks
- Think outside of your own area
- Imagine before release a very bad thing had happen (“pre-mortem” meeting)
- Importance of instrumentation
- Prepare in advance for stressful days (release, etc), prescale
- Monitor what your users are experiencing, to proper prioritise fixes. If the user doesn’t access it, is it worth fixing?
- Bring observability as part of the dev process
For some strange reason, after all the unknown talk, I got a bit disappointed that Damien Marshall didn’t sing “Into the unknown“. But it’s just me, I guess.
The hidden world of Kubernetes by David Gonzalez
David is a Google Dev Expert at GCP, and he went into the metaphore that Kubernetes is the equivalent of an airport. There can be many kinds of planes, but airports ned to be standarised to accept all kinds of them, and they are incredibly complex structures that streamline the operations of the planes.
Kubernetes is an API as DSL modelling of the concept of the software deployment
If you are embarquing into Kubernetes (and he defended that many companies doesn’t need to, and can work with a simpler orchestration approach), you need to transform your processes to fully embrace, as some of the traditional software practices are opposed.
He set a list of ideas to make it work:
- Fully embrace the platform. That means both Kubernetes and the underlying cloud platform. If you are in AWS (or Azure, or GCP), go “all-in”
- Deliver often and. beready to roll back
- Don’t run Kubernetes if you don’t have the scale or resources
- “Build it and they’ll come” doesn’t work. You’ll need an SRE team that deal with. the platform, where 90% of the work should be automated, and the 10% missing will be plenty to keep everyone occupied
He described that the SRE team is key, and they need. tobuild the platform, but also evangelise about it, help teams with manifests (again, fully embracing all the features that Kubernetes offers). The real value of an SRE team is that is able to scale logarithmically as the rest of the company grows linearly. In non-technical terms this means that a small team can support a pretty big organisation.
Innersource, open collaboration in a complex world by Clare Dillon
Clare talked about the concept of Innersource, which, as she described it is “Open Source within a firewall“, using the concepts and practices of Open Source inside a company.
The main practices are that the code is visible to everyone in the company; there’s a big focus in documentations (like READMEs, roadmaps, etc); to contribute externally from a team is possible and even welcome (including details like enabling mentoring or reviewing the code) and that there’s community engagement.
Right now is gaining quite a lot of traction, thanks to different aspects, like the increase in remote and hybrid work; the war on talent and ability to attract people used to work in Open Source already; and the gains in code reusability and developer productivity.
Automating observability on AWS by Luciano Mammino
Luciano described an observability tool that he has been working on that is aimed at serverless applications in AWS, SLIC watch.
In essence, is a tool that will enhance existing definitions of applications in serverless through Cloud Formation to add observability tools like CloudWatch, X-Ray and other available options. It aims to solve the 80% of the definition work, by giving a good “starting point” that then needs to be tweaked.
It sounded like a great tool for the specific case, and they are working in expanding it to improve it.
Final thoughts
As in previous years, and as you can see by the amount of notes that I take (i can assure you that I have many more in my notebook), I think is a fantastic conference and it’s full of thought-provoking ideas. I may not agree with all of them, but they make me think, which I appreciate.
If you are interested in the difficult art of releasing software and can be around Dublin in September, I definitively recommend attending. It’s an intense day, but full of ideas that will keep your head busy for a while afterwards!
The unavoidable review of Indiana Jones and the Dial of Destiny
New Indiana Jones movie! Amazing!
It seemed that we will never got another one after Last Crusade Kingdom of the Crystal Skull! 15 years already! I’ve always been a great fan of the character, and of course I had to go watch the new adventure.

What’s my opinion? Well… it’s fine. Is it GREAT? I don’t think so. But it’s a fun and enjoyable adventure movie, 100% worth watching. Does it raise to the level of the best instalments of the saga? No, but because those are the best of the best in their genre, and arguable some of the best movies of the last 50 years.
Raiders of the Lost Ark is an absolute masterclass in pace, cinematography and action pieces, and a movie that spawned countless clones with leather-jacketed adventurers in the jungle. Last Crusade is a perfect comedic adventure full of soul with a bulletproof script.
Dial of Destiny is pretty solid, and, in comparison with Kingdom of the Crystal Skull (the universally considered weaker of the first four movies), it’s pretty consistent. It maintains a good level all the time. Kingdom of the Crystal Skull is irregular in comparison. It has great heights, like the motorbike chase scene, and astonishingly ridiculous lows, like the infamous “vine swinging in the jungle” one.
I appreciate Kingdom of the Crystal Skull for trying to update the setting from the 30’s serials to the 50’s B-movies about aliens, with the background of the “red scare”. But it’s a big risk that ultimately doesn’t pay off as well as it should when looking at the series as a whole.
Compared to that, Dial of Destiny fits more traditionally in the “Indy feel”. There’s evil Nazis and a couple of McGuffin artefacts to chase around the world. Though it takes place in the end of the sixties, there’s no effort in updating the movie to include elements of a period-accurate Bond movie.
From here on, we move to SPOILER territories. If you want to keep up to here, the basics are “The movie is fun and worth watching in a movie theatre if you’re a fan of the character, but it’s not going to blow your mind“
Now, on to the spoilers-filled section, with a list of things I liked and things I didn’t like, always in my personal opinion!
Read MoreRevisiting Star Trek Nemesis
I recently rewatched ST: Nemesis, which I went to see at the movies, so around 20 years ago.
(sorry, there will be some spoilers, I’ll assume that you’ve seen the movie)
My impression back then was that it was not great and broke the “even/odd Star Trek movies rule”. This rule states that the odd Star Trek movies are bad and the even ones are good, so after Star Trek Generations (I’m starting at The Next Generation movies to not overcomplicate this: number 7 and therefore bad), it was Star Trek First Contact (number 8 and good), then Star Trek Insurrection (number 9 and bad) and then Star Trek Nemesis, which should be good, but it wasn’t.
The movie back then was not very successful on the box office, and more or less ended the run of Star Trek on cinemas, which had been quite long up to that point, and required a reboot years later. While franchises never truly end, I think we can agree that there was a significant pivot around this era, to the point that never series and movies are sometimes referred as “NuTrek”.
So, I just rewatched it with low expectations.
And I quite like a lot about it!
It’s probably not a “good movie” by any standards, and probably not even a “good Star Trek movie”, and it has a bunch of problems, but I think it has several good points that I actually liked
- First of all, if feels like a “premium TNG episode”, but in the good way. The production designs are in line to the things we have seen. The Romulan Senate, for example, totally belongs to the aesthetic of the series, but obviously the budget of a movie helps in making it bigger and bolder.
- The space battle in particular is quite well done, feeling bigger and better, but following somehow the parameters of “Star Trek space battles” of the era.
- The chemistry between the actors is truly something. One of the high points of TNG was the fact that the whole cast were good friend. They really enjoyed working together, and that shows on screen.
- It’s quite interesting to see a young Tom Hardy! He doesn’t look anything like Patrick Stewart, though…
- There are some truly great illumination. It also differs from the “TV series” look. I liked in particular this scene where they focus on Troi’s eyes (the scene can be watched in YouTube)

Sure it’s a bit cheesy, but I think that these kind of “dramatic illumination” has disappeared, and I find the current photography quite bland in general, so going back to some older movies I get actually quite excited on times where they are overly dramatic. I think it adds a lot of character.
- The ending with Data’s sacrifice felt like a good ending for the character. It is not oversold, but it was done totally on character. I also liked the previous scene where Data jumps from one ship to the other.
- I liked the avoidance of destroying the Enterprise, instead leaving it severely damaged. Destroying the Enterprise in the movies has become a trope on itself, and you can see them here that they were close to cross the line.
At the same time, I also think that it has some problems:
- The script try to do too many things at the same time, and the plot gets confusing because of that. The movie also appears to have been cut quite aggressively. While there are some themes in regards of copies and “what makes each one unique” in the characters of B4 and Shinzon, but I don’t think are well developed. I don’t think there’s anything interesting about the fact that the antagonist is a clone of Picard or it’s used in any meaningful way.
- The “mental invasion of privacy” (to not use worse words) is particularly strange, and appears to be totally out of place in the Star Trek universe.
- The CGI shows its age. It’s not particularly terrible given that it’s a 20 years old film, but it’s curious how old digital effects are so noticeable, and lack the warmth of old practical effects, even when not great.
- Too many actors that are not properly used. In a TNG movie is unavoidable that some of the cast is going to have minimal screen time, like Gates McFadden or LeVar Burton here. There’s simply no space in a motion picture for such a big TV cast. But I think that Ron Perlman and Dina Meyer are massively underused here. The Viceroy character in particular appears to be the equivalent of a James Bond henchman, but lacking something that would make him memorable.
In summary, I enjoyed watching it, and I think that it improved from my memory of it, which is always a nice effect.
