
Interview in the Network Automation Nerds Podcast
I had a nice chat with Eric Chou in his Network Automation Nerds Podcast about some of the topics that I’ve talked about on my books, like Software Architecture and Automation. We also covered topics like how I started my journey into Python or the difference between different roles.
The chat is available in podcast format

#055 Embracing Change in Tech with Ethan Banks and Drew Conry-Murray – Part 2 – Network Automation Nerds Podcast
- #055 Embracing Change in Tech with Ethan Banks and Drew Conry-Murray – Part 2
- #054 Embracing Change in Tech with Ethan Banks and Drew Conry-Murray – Part 1
- #053: Innovation in Network Automation with Damien Garros: The OpsMill Solution – Part 2
- #052: Innovation in Network Automation with Damien Garros: The OpsMill Solution – Part 1
- #051: Unlocking Network Engineering Insights with Dr. Russ White, Part 2
Here for a direct link to the podcast.
and in video
Again, here is a direct link to the video.
I think there was a lot of interesting topics and I hope you enjoy it!
A year in weightlifting
At the end of 2020 I had to take very serious action to lose weight, for medical reasons. The COVID pandemic and being home I guess made my body mass to go over some threshold and the doctor got a pretty scary chat with me.
So I started talking with a nutritionist and start a plan.
The spoilers of that is that it worked. I have lost so far almost 40Kg since I started a year and a half ago. I’m close to what I considered when I started “the ideal situation”, so I’m still working on it.
For the first 6 months, more or less, the main focus was the food. I anyway started walking round 5 km every day, something that I missed since the start of lockdown. I used to walk to work, and I always liked it. Progress was quite noticeable during that time.
After that, the nutritionist told me to start doing strength exercises to increase my muscular mass.
I had never been doing anything like that. I’ve never really been a sports person, and it all has been a novelty. Now that I’ve been pretty actively working out for a year, I’m going to share some of my ideas of the process.
First of all, I’ve been working out mainly at home. I went for a month to a gym, but I quickly preferred to exercise at home instead. It’s faster and more convenient, instead of moving to a different place, and I can integrate it better in my day. It’s true that you have more resources in a gym, but for most of the time you are not using them fully.
Probably because I’m not use to attend, there are a lot of “gym etiquette” stuff that I don’t know. Nothing that cannot be learnt, but I never got to the point of being comfortable. I guess that also at home I’m less worried of the interaction, having to wait to use something, blocking someone for using it or even being judged by others.
In any case, I found out that I like working out with the Apple Fitness + videos. The system itself is well constructed, can be started on different screens, from the phone to a TV using Apple TV. It connects to your watch and gets heartbeat and calories info. I’m already invested into the Apple ecosystem, so it’s natural to use. In regard to the exercises, they just require using some dumbbells and are easy to do at home, not even demanding too much space. The instructors are nice and “human”, meaning that they don’t look like robots, performing mechanically impossible feats.
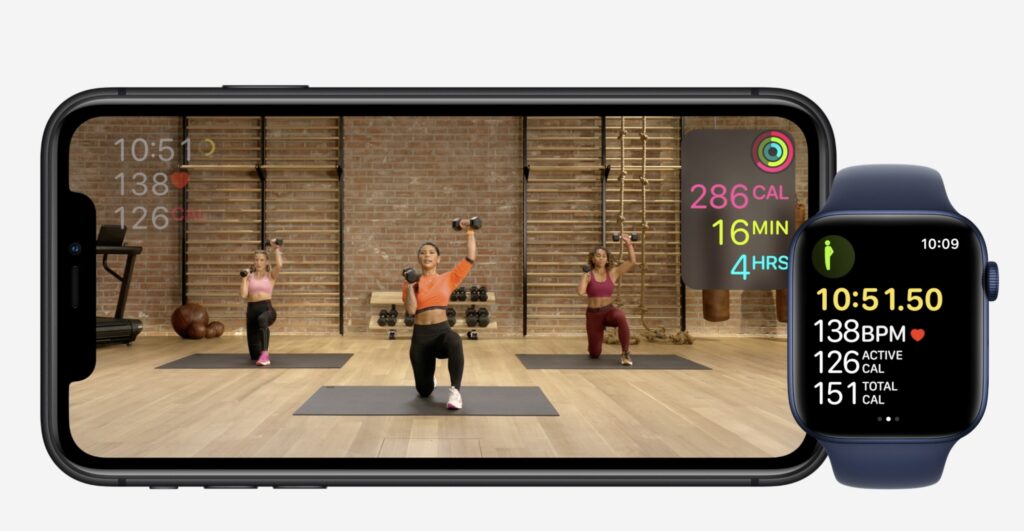
All exercises are properly explained, including some modifications to make them more accessible.
I had to buy some dumbbells, but it’s a relatively small investment. I got some that can be expanded with extra weight, so I was able to increase the load over time. They are also as small as possible, to save space storing them.
Routine
Simply motivation is not a great way of maintaining the effort long term. In my case, the key element is to create a habit that I can sustain.
This need to not rely too much on motivation, and instead work on repeating things over and over, even if you don’t feel like you should do it.
This includes generating some space and time where you can exercise. For example, I go out for a run after finishing work. Reserve time in your calendar, if necessary.
I never want to do the exercise, and I never end up feeling energised by it, as other people do, but I sort of do it out of duty. I feel good when I finish from the point of view that it is something that I have to do, no matter what. Over time, this becomes more and more natural to do, even if not a single day you are truly wanting it to do. It similar to brush your teeth. It’s not something that you think too much about doing or not, you just do it.
Another key element for me at least is that I’ll do it, but not everyday I have the same energy and that is fine. Somedays I’ll take it a bit easier if that’s the case, but the counterpart is that when I’m feeling like I can do it, I will go fully. And the interesting part is that there are more good days than bad days. The idea is to constantly challenge yourself, to the point that sometimes it gets a bit scary about whether you’ll be capable of doing it.
Part of my habits is weighting myself every day. I don’t recommend it, as it can go up and down for not clear reasons, and sometimes can be demotivating. That said, I like the daily data and to me is easier to do that instead of doing a weekly weight, which is probably best for most people. It is important to do it at the same time and in the same conditions. After a while, it provides valuable trends.

Ah, the wonders of getting feedback…
I think that after all this time, I have the habit quite solidified, but it doesn’t mean that each individual day is easy. It is not. But I do it because I am used to it.
After a year
I’ve been quite consistent with exercising and diet over the last year. Well, over the last year and a half in most regards. Anyway, this has been my first experience with doing exercise regularly and, in particular, trying to build up muscle. This has been a process with a number of surprises, or comments.
- Honestly, I haven’t perceive a massive amount of change in how do I feel in general. Previously I wasn’t feeling bad in any obvious aspect, and I was active walking a lot, which I think allowed me to not feel tired all the time. A few areas have improved, though. I can definitively perceive an improvement is carrying groceries and other bags, which is quite noticeable. It also helped with RSI problems on my hands. Some times I had before some soreness in my knees that seemed to go away, but it was rare to start with.
- Measurements, on the other hand, have improved quite noticeable. Things like blood pressure, blood sugar, and other objective things are much much better. These things are difficult to perceive subjectively, but are big improvements in overall health.
- Physically there’s obviously a big change. Not only in less weight, but this is the first time in my life that I can see some muscle in the upper body. I’ve always been naturally muscular in my legs, probably combined with the fact that I’ve always liked to walk, but my arms and shoulders feel strange having some sort of definition.
- On that regard, I’ve been surprised on location and function of some muscles. It’s weird that you don’t really know how your body actually IS. For example, the location of the biceps is a bit different that I thought, as it is sightly inclined in your arm, towards your chest, instead of being perfectly pointing forward. That surprised me, for some reason.
- The one muscle that surprised me the most is the triceps. This is the muscle on the back part of your upper arm, which works to extend it. It works in opposition to the biceps. This muscle sort of moves around the arm, when the arm is extended, it is more prominent on the upper part of the arm, closer to the shoulder. This is actually when it’s performing its function. But when the arm is contracted, it is more prominent closer to the elbow. It works in a very different way than the biceps, which is more in a contracted/relaxed way, as you’ll expect.

- Even feeling different muscles that you are used to. Certain exercises will force you to use muscles that you have but are not aware. Also exercising in certain way will make you way more aware on where specifically the muscle is and when you are using it, sometimes referred as mind-muscle connection. And yes, sometimes the next day there are parts of body you didn’t even know that hurt.
- Another weird thing of your body is that it’s not entirely symmetric. When you develop muscle, it won’t appear in both sides of your body at the same time. It’s small, assuming a symmetric training, but you can notice it, which is quite strange.
- Working out regularly and hard makes you appreciate the insane amount of effort involved on it. And pure invested time. You try to reach your limit constantly and it never becomes easier. Perhaps the habit makes it more manageable, as you know what to expect, and after a while, the recovery is faster. But each and every minute costs. I could use some good-old 80s montage to speed up the process.
- My least favourite exercise are push ups. They are awful. I was really really bad doing them, so I started doing them more often. Adding extra push ups here and there to actively improve the execution. I still hate them, but I notice a great improvement in doing them. There’s a lesson there, but I still don’t like doing push ups.
- Resting is a very important part of the process that should not be overlooked. Given that I take daily measurements, I can see that a day where you don’t rest as you should (this happened for example for some work-related problems where I needed to stay up at night) it reflects quite clearly on your weight. It really helped me to try to get my 8 hours of sleep every day, as well as respect rest days.
- The moment you search some information online you start seeing an insane amount the videos recommended. It’s clear that the world of fitness is really big, and full of all kind of things, from tips to products. One can get in a rabbit hole of YouTubers talking about supplements, proper form or all kinds of tips. It’s also easy to see that there’s a lot of shady advice out there.
- This happens in combination to another interesting thing. Clearly you can start feeling body dysmorphia, meaning that you are way more aware of your body and the parts that you don’t like about it. As you start being bombarded by videos and images of people with much better looking bodies than yours, it’s unavoidable to make comparisons. I’ve never been much for being worry about how my body is, but I can feel now to be more aware of that. You can clearly see how this can get out of control.
- This happens even if my objective is not really to be “jacked” or “muscular” or anything like that. But it’s somehow unavoidable to notice things that I wasn’t noticing before.
It’s still a process. I am still a newbie in all of this, and I still feel like I have a lot to learn and a lot to go. I’m still surprised that I am following this, and we’ll see how it goes after year two…
The Many Challenges of a (Software) Architect
Software Architecture is a fascinating subject. The objective of a solid architecture for a system is to generate an underlying structure that is separates components in a meaningful way, but at the same time, is flexible to allow the system to grow in capacities and functionalities. That it’s performant, reliable and scalable within the required parameters, but it’s as easy to work with as possible.

Even worse than that, the work is to do that at the same time that a myriad of other competing priorities are being done, new functionalities are added and costs kept under control.
And, of course, while being as simple and elegant as possible.
In essence, nothing new to anyone doing software development…
After all, any program, even very small ones, have certain architecture in their design. Even when tiny, any structure in place can be rightfully understood as the architecture of the system.

The main difference when we talk about Software Architecture, is that usually we refer to systems that have already certain size, so multiple people are working on them. The view changes from “how much can fit in the head of one person” to “how the work can be divided so it can be done effectively”. A single person can have a strange way of doing things, but it makes sense for them.
And that’s the crucial element, the involvement of different people, and more commonly, different teams in the process. No longer esoteric divisions that make sense only for their creator are a good idea.
I’ve been involved into a lot of architecture discussions and processes in the last 3 to 4 years. First, as part of a group that was trying to give technical direction across the company where I was, and in my current role as Architect, where is a big part of my daily duties.
And it’s almost all about the communication. For example:
- A very difficult task is to transmit the vision in your head or design to different people that may have other priorities and perhaps they don’t see things in the same way. Most of the time is because they don’t perceive the improvement in the same way, as they are focused in other tasks.
This is similar to trying to teach someone to use a shortcut to copy/paste instead of going to the menu and select it. Sure, it’s faster, but they don’t see the point because they are focused in writing and not in learning how to be faster. A lot of architectural decisions are about making changes for improvements that may not be immediately obvious, like making processes more resilient. - It’s very common to be between two different teams trying to make them cooperate. But this is easier said than done, because each team have their own agenda.
Another important detail is that there’s no hierarchical relation, so at best you can only influence the teams and that’s a difficult skill. - It’s great to have something designed, point a finger in the air and say: “Make It So”, but you need to do follow up on what’s the progress on the different tasks and ensure that the actual implementation of it makes sense and achieves the objectives.
- There’s also the need to be self-reflective and acknowledge that every step needs to be evaluated critically to be sure that it’s in the right direction.
The objective of work in the Architecture of the system is not to mandate top-down a Perfect Design™, no matter what. Instead, is to help the different teams into work better. There needs to be feedback in the process.
Surprise, it’s all dealing with people, it’s all soft-skills! Influence, teaching, negotiation, communication… While the tech skills and experience are obviously a prerequisite, in the day-to-day the muscles that gets more flexed are the the soft-skills ones.

A consequence of this is that pressure and struggle manifest in a different way, as you are not only depending on something that a machine can do, as typical for engineers, but on what other people can do.
It’s a fascinating work, though. I like it a lot as, when everything comes together is great to feel that you are helping a lot of teams to work better together and to make your vision on what direction the system should follow gets implemented.
And you also get to draw a lot of diagrams! Diagrams everywhere!
Futures and easy parallelisation
Here is one small snippet that it’s very useful when dealing with quick scripts that perform slow tasks and can benefit from running in parallel.
Enter the Futures
Futures are a convenient abstraction in Python for running tasks in the background.
There are also asyncio Futures that can be used with asyncio loops, which work in a similar way, but require an asyncio loop. The Futures we are talking in this post work over regular multitask: threads or processes.
The operation is simple, you create an Executor object and submit a task, defined as a callable (a function) and its arguments. This immediately returns you a Future object, which can be used to check whether the task is in progress or finished, and if it’s finished, the result (the returned value of the function) can be retrieved.
Executors could be based in Threads or Processes.
The snippet
Ok, that’s all great, but let’s go to see the code, which is quite easy. Typically, in your code you will have a list of tasks that you want to execute in parallel. Probably you tried sequentially first, but it takes a while. Running them in parallel is easy following this pattern.
from concurrent.futures import ThreadPoolExecutor
NUM_WORKERS = 5
executor = ThreadPoolExecutor(NUM_WORKERS)
def function(x):
return x ** 2
arguments = [[2], [3], [4], [5], [6]]
futures_array = [executor.submit(function, *arg) for arg in arguments]
result = [future.result() for future in futures_array]
print(result)The initial block creates a ThreadPoolExecutor with 5 workers. The number can be tweaked depending on the system. For slow I/O operations like calling external URLs, this number could easily be 10 or 20.
Then, we wrap our task into a function that returns the desired result. In this case, it receives a number and returns it to the power of two.
We prepare the arguments, like in this case the numbers to calculate. Note that each element needs to be a tuple or list, as it will be passed to the submit method of the executor with *arg.
Finally, the juicy bit. We create a futures_array submitting all the information to the executor. This returns immediately with all the future objects.
Next, we call the .result() method on each future, retrieving the result. Note that the result method is blocking, so it won’t continue until all tasks are done.
Et voilà! The results are run in parallel in 5 workers!
A more realistic scenario
Sure, it will be strange to calculate squared numbers in Python in that way. But here is a sightly more common scenario for this kind of parallel operation: Retrieve web addresses.
from concurrent.futures import ThreadPoolExecutor
import requests
from urllib.parse import urljoin
NUM_WORKERS = 2
executor = ThreadPoolExecutor(NUM_WORKERS)
def retrieve(root_url, path):
url = urljoin(root_url, path)
print(f'{time.time()} Retrieving {url}')
result = requests.get(url)
return result
arguments = [('https://google.com/', 'search'),
('https://www.facebook.com/', 'login'),
('https://nyt.com/', 'international')]
futures_array = [executor.submit(retrieve, *arg) for arg in arguments]
result = [future.result() for future in futures_array]
print(result)In this case, our function retrieves a URL based on a root and a path. As you can see, the arguments are, in each case, a tuple with the two values.
The retrieve function joins the root and the path and gets the URL (we use the requests module). The print statement work as logs to see the progress of the tasks.
If you execute the code, you’ll notice that the first two tasks start almost at the same time, while the third takes a little more of time and start around 275ms later. That’s because we created two workers, and while they are busy, the third task needs to wait. All this is handled automatically.
1645112889.005687 Retrieving https://google.com/search
1645112889.006123 Retrieving https://www.facebook.com/login
1645112889.2814898 Retrieving https://nyt.com/international
[<Response [200]>, <Response [200]>, <Response [200]>]So that’s it! This is a pattern that I use from time to time in small scripts that very handy and gives great results, without having to complicate the code to deal with cumbersome thread classes or similar.

One more thing
You may structure the submit calls with the specific number of parameters, if you prefer
arguments = [('https://google.com/', 'search'),
('https://www.facebook.com/', 'login'),
('https://nyt.com/', 'international')]
futures_array = [executor.submit(retrieve, root, path) for root, path in arguments]
result = [future.result() for future in futures_array]The *arg part allows to use a variable number of arguments using defaults depending on the specific call, and allow for fast copy/paste.
“Python Architecture Patterns” now available!
My new book is available!
Current software systems can be extremely big and complex, and Software Architecture deals with the design and tweaking of fundamental structures that shape the big picture of those systems.
The book talks about in greater detail about what Software Architecture is, what are its challenges and describes different architecture patterns that can be used when dealing with complex systems. All to create an “Architectural View” and grow the knowledge on how to deal with big software systems.
All the examples in the book are written in Python, but most concepts are language agnostic.
This joins the collection of my books! I’m quite proud to have been able to write four books already…

Python Automation Cookbook for only $5!
There’s currently a Christmas offer in Packt website when you can get all ebooks for just $5 or 5€.
It’s a great opportunity to get the second edition of the Python Automation Cookbook and improve your Python skills for this new year!

Also available, of course, is Hands-On for Microservices with Python, for people interesting in learning about Docker, Kubernetes, and how to migrate Monolithic services into Microservices structure.

A great opportunity to increase your tech library!
Still working from home after all those years

We are all experts in working from home now, right?
Since March 2020 we’ve been stuck in this strange situation where time has stopped and we are working regularly from home, at least almost everyone in the software industry. Because we were already a bit ahead of the curve.
I was seeing more and more remote work since at least a few years before. The first time that I had any meaningful remote work was around 2005. Back then, I was working as a consultant and I had regular meetings with customers onsite, carrying a laptop. Somedays I would finish the reports and other work from home, as it didn’t make sense to get back to the office. It was a small company, but most people will have similar experiences, some days not going to the office.
It took a while for me to encounter back in a situation where remote work was common, but in the last half of the 2010 it was more and more common. I knew some people that moved countries and kept their jobs, so they work mostly remotely. And on-call work routinely require people being able to connect from their homes, setting up a VPN, etc.
That was growing over time. Three years ago, it was common where I worked to work from home one or two days of the week, and I’ve been taking advantage of going for a month overseas to Spain and keep working remotely most days.
But now it has taken a sudden acceleration, and we experienced quite a lot of work from home. I’m going just to put in writing some of the elements I think are quite important in this, or at least they are for me.
Space.
While for working sparingly one day or two you can sit on the kitchen table or from the coach, this is hardly a sustainable option. You need a dedicated space that can be used for working effectively day after day.

“Python Architecture Patterns” book announced!
We are getting close to the end of the year, but I have great news! A new Python book is on the way, and will be released soon.
Current software systems can be extremely big and complex, and Software Architecture deals with the design and tweaking of fundamental structures that shape the big picture of those systems.
The book talks about in greater detail about what Software Architecture is, what are its challenges and describes different architecture patterns that can be used when dealing with complex systems. All to create an “Architectural View” and grow the knowledge on how to deal with big software systems.
All the examples in the book are written in Python, but most concepts are language agnostic.
This new book is related to my previous one “Hands-On Docker for Microservices with Python“, as it also deals with certain architecture elements, though in the new book it has a broader approach.
With this book, I will have four published technical books, well, three if you count the two editions of the Python Automation Cookbook. I count them as two as the writing effort was there!
I hope that it will be fully available soon, so far it’s only in pre-sale. Stay tuned!
Basic Python for Data Processing Workshop
I’ll be running a workshop at the European ODSC this 8th of June.

The objective of the session is to provide some basic understanding of Python as a language to be used for data processing. Python syntax is very readable and easy to work with, and its rich ecosystem of libraries makes it one of the most popular programming languages in the World.
We will see some common tools and characteristics of Python that are basic to analyze data, like how to import data from files and to generate results in multiple formats. We will also see some ways to speed up the processing of data.
This workshop is aimed at people with little to no knowledge of Python, though some programming knowledge is required, even if it’s in a different language.
Session Outline
Lesson 1: Basic Python.
Introduction to basic operations with Python that is basic for treating data and creating powerful scripts. Also, we will learn how to create a virtual environment to install third-party libraries and discuss how to search and find powerful libraries. It will also include creating flexible command-line interfaces.
Lesson 2: Dealing with files
Read and write multiple files, from reading CSVs to ingest data to writing HTML reports including graphs with Matplotlib. We will also cover how to create Word files and PDFs.
Lesson 3: Efficient data treatment
Learn how to deal with data in an efficient manner in Python, from using the right data types, to use specialized libraries like Pandas, and using tools to run Python code faster.
Background Knowledge
Programming knowledge, even if it’s intro in Python
Got interviewed as PyDev of the Week!
I got interviewed as part of Mike Driscoll’s PyDev of the week series. You can check the interview here
