
Podcast Wrong Side of Life
I started a new podcast with Sana Khan (@LegalSana_Khan and http://sanakhanwrites.com/), talking about things that interest us, like society stuff, tech, laws, movies… We recorded already a few episodes, so perhaps you want to take a look.
You can listen to it in http://wrongsideoflife.com
It’s also available in Apple Podcasts, Spotify and you can search it directly in common podcast applications like Overcast or Castro.
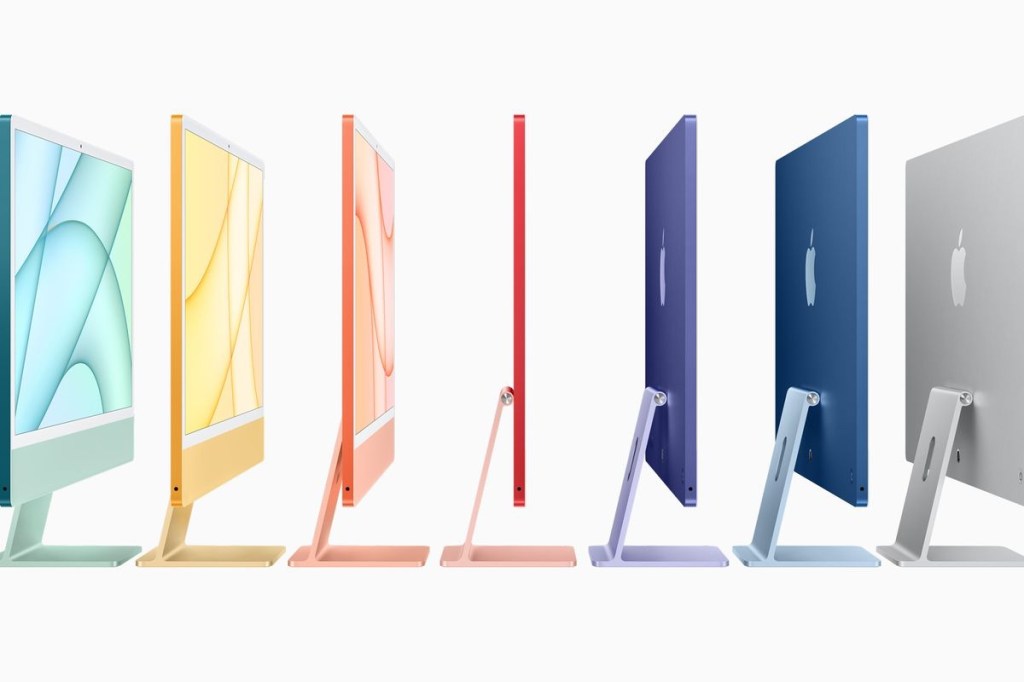
Colourful iMacs again

I really love the new iMacs. The design looks amazing and it reintroduced something long missing in Apple computers. Vibrant colours

I’ll be waiting to the “big” iMac (the current-27 inches size) which I suspect will be renamed as iMac Pro or iMac Plus to get clarity in the product line.
The rest of introduced details are what you’ll expect on this iteration:
Apple Silicon, still M1 chip. Probably a new chip will be presented in Autumn, likely after the introduction of the new iPhone. The Apple Silicon appears to have two models, one for all the “consumer” products, with the introduced M1 products so far (Mac Mini, iPad Pro, MacBook Air and iMac) and a more powerful, “pro”, option (bigger iMac, MacBook Pro) Mac Pro is a special case that probably will get either multiple “pro” chips or a special, “top” chip.
The possibility of using Touch ID in the wireless keyboard was unavoidable, as it’s a really convenient feature on laptops. Same for the webcam, which was due for upgrade. Next step will be to incorporate Face ID as well.
The new design also points to what to expect in next years. Thinner, lighter design which will remove the chin at some point. Same for bezels, which will become smaller. The addition of an external power adapter is strange, though it moved the Ethernet plug out of the back, and I imagine makes the screen lighter.
I hope that it has the same or similar colours than the introduced ones. because they look amazing… And the matching mice, trackpads and keyboards are lovely
macOS, Apple’s core

These days mark the 20th anniversary of Mac OS X, later renamed as macOS.
Really the underlaying tech is the same, but the naming allows them to move past 10.X into other unexplored territories.

There’s a lot of talk these days about Macs, specially after the introduction of Apple Silicon, which certainly is an exciting move. There was some years where there was debate over the tech world on whether Apple should drop the Macs and focus on iPads or iPhones. Because the old Personal Computer paradigm is dead, right?
Nonsense.
While the famous analogy by Steve Jobs about cars and trucks is valid (just because there’s more cars that doesn’t mean that the trucks are getting nowhere, as they are more suited to certain tasks), I think it doesn’t capture really the essence of why smartphones and tablets are not really replacements for Personal Computers (being that desktops or laptops)
It’s not only that the virtual entirety of software that runs in iPhones and iPads is built in Macs. It’s that their builders uses Macs for their main workflows.
Sure, there’s some people that can run their work in iPads or even 90% of their flow in smartphones. But the form factor makes much more productive to work in a full personal computer. With a good keyboard, with key shortcuts, with more space in the screen. The fact that the iPad uses now an external keyboard is prove of that.
Obviously, macOS is tailored for all those elements, in the same way that the iPhone is for being handled with a hand, with less precision input. Writing a long email becomes more complicated, copy/paste is sensibly more frustrating. The Mac makes all those actions easier.
And that’s why the Mac is the lynchpin of everything at Apple. Because it’s at the source of all other products. It’s where the iPhone is designed and where the iPad and Apple TV apps are written.
macOS is Apple’s core.
PyLadies Architecture Talk
I gave last November an online talk (at 2020 demands) in the PyLadies Dublin about the general software architecture that we are using in one of the projects that I’m working on, a proctoring tool for online exams. It’s on the minute 26 go the video, the other talks are also quite interesting.
(the talk is directly accessible by the URL https://www.youtube.com/watch?v=UIY-Z7daEG0&t=26m10s )
Hope you like it!
The price of a bad connection when working from home
I wrote a guest post in the B2beematch blog, about some of the challenges in working remotely regarding connectivity.
The COVID-19 pandemics have greatly impacted our life’s, and people lucky enough to be able to work from home face a big challenge in remaining productive in dire times. I tried to go on some of the elements that impact in the connectivity and network capacities to remain online, which is crucial on remote working.

You can check the post here.
2nd Edition for Python Automation Cookbook now available!

Good news everyone! There’s a new edition of the Python Automation Cookbook! A great way of improving your Python skills for practical tasks!
As the first edition, it’s aimed to people that already know a bit of Python (not necessarily developers). It describes how to automate common tasks. Things like work with different kind of documents, generating graphs, sending emails, text messages… You can check the whole table of contents for more details.
It’s written in the cookbook format, so it’s a collection of recipes to read and reference independently. There are also chapters combining the individual recipes to create more complex tasks. I tried to make it accessible and practical.
This new edition has the whole content reviewed. It also includes three new chapters. They cover cleaning up data, adding tests to the code, and how to start using Machine Learning. The ML chapter uses existing online APIs. This is a great way to great results without having to learn complex math.
The book is available for purchase in the Packt website as well as Amazon.

Even if it’s a second edition, it’s impressive how much work goes into writing a book. This book joins the first editon and the Hands-On Docker for Microservices with Python. This means that I have three published books, which is supper exciting.
Brexit

I know politics is not the usual subject in this blog, but I want to make an exception. We are right now at 31st of January 2020, the day the United Kingdom leaves the EU.

A bit of background first: I am a Spaniard that has been living in Ireland for the last 10 years. I’ve always been influenced by British culture, I guess through music and literature, and at some point I was considering moving to the UK for work.
When I read the results of the referendum, back in 2016, I was utterly in shock. I think it was the time I’ve been most in disbelief of a political event ever. It felt like completely surreal. So much that I changed my Internet avatar to include an EU flag. This may result silly for you, but I keep my avatar as my persona, and I’m very protective about it. To put things in context, the only other time I added a flag to my avatar was due the train bombing attacks in Madrid in 2004. I feel deeply European, and feel “at home” not only in Ireland, but also when travelling to France, Italy, Portugal or Germany…
And this whole process of the Brexit is so so frustrating. I’ve been keeping a close eye to the politics of UK during the last years, and I’ve been surprise by the sheer misunderstanding of, well mostly everything.
From the point of view of Ireland, that also has troubling implications. The Irish Border is an incredibly complicated problem, but it was dismissed for a long time, and even now I’m not sure most English politicians even understand properly the issue.
This post has been drafted for months, trying to capture my thoughts and feelings, but it’s just so difficult to write something that doesn’t feel incredibly silly, outdated or redundant.
During this almost four years, I think we collectively pass through a lot of states, from incredulity to relief, to acceptance to Schadenfreude, sometimes all at the same time. This long and complicated process has also exacerbated the nationalistic feelings, something that I don’t like and even scares me. Probably at this point everyone is tired and happy to see it moving to the next stage.
There’s still emotion attached. This rare moment in the European Parliament was particularly moving
Still, inside of me there’s still that shock, and the nagging feeling that this is a step in the opposite direction on where I’d like to move… It’s also the start of another part of the process, full of painful negotiations, and likely disappointments…
This is not over yet. And won’t be for a while…
Una década trabajando en Irlanda en Desarrollo Software

Hoy hace diez años que me mudé a Dublín, a empezar un nuevo trabajo.

Photo by KML on Pexels.com
Han sido diez años de mucha actividad, y de gran desarrollo personal y profesional, con cuatro trabajos distintos. Además, coincide casi exactamente con “los años 2010s”. Algunos detalles
- Lógicamente, el inglés que tengo ahora no es el de hace diez años. Aunque me sorprende que siempre haya momentos que no entiendes, o frases que te lías. Esto es más ser quejica que otra cosa.
- He desarrollado todo este tiempo mayoritariamente en Python, que era mi objetivo inicial. Es un lenguaje que me sigue encantando, y además, no ha hecho más que crecer en esta década. En todo este tiempo, obviamente, he aprendido mucho sobre cómo usarlo. Mi código es mucho más pythónico ahora que antes.

- He sido relativamente activo en la comunidad local de Python, y he dado charlas tanto en reuniones mensuales como en las PyCons de estos años. Sólo falté a la última del año pasado (2019) por tener otro compromiso ese fin de semana.
- He aprendido muchísimo sobre temas como servicios web, escalabilidad, bases de datos (SQL y NoSQL), arquitectura de sistemas, microservicios, DevOps, monitorización, y mil más… Y no sólo tecnologías puras y duras, he tenido compañeros fabulosos de los que aprender cosas como gestión de conflicto, atención al cliente, cómo tratar otros desarrolladores, etc.
- Hablando de compañeros, he estado en equipos realmente internacionales. No sólo gente de toda Europa, sino de todo el mundo. Trabajé unos meses con un equipo en el que había componentes de los cinco continentes. Aprendes mucho y el mundo se hace un poco más pequeño, relacionas lugares remotos con gente que conoces.
- He trabajado en empresas que gestionaban millones de usuarios concurrentemente. El trabajo de preparación y gestión que hay detrás de eso es impresionante.

- ¡He escrito dos libros! De los que, además, estoy muy orgulloso del resultado: Python Automation Cookbook y Hands-On Docker for Microservices with Python

- Me pasé definitivamente al lado oscuro de usar Mac y productos Apple a principios de la década y hasta ahora… El que sean “Unix con un interfaz bonito” es maravilloso para el desarrollo.
- Revisando estos antiguos artículos sobre las cosas que uso para trabajar, es curioso que sigo usando prácticamente lo mismo. Ahora que tengo ya bastante práctica con Vim va a costar cambiarlo…
- He viajado bastante. Por trabajo y fuera de él. A muchos sitios como Canadá, Estados Unidos, Emiratos, Alemania, Italia, Portugal…. Y muchos sitios en España.
TECNOLOGÍAS
En términos de tecnologías, las dos que más me han marcado, en el sentido de ser una revolución en cómo trabajo, son tanto Git como los servicios web de Amazon (AWS), a principio de década y Docker/Kubernetes hacia el final.
- Git se ha convertido en el estándar de facto de control de versiones, en gran parte por el gran trabajo de GitHub.
- AWS es increíblemente relevante, y permite usar infraestructura (mayoritariamente, pero no limitado a, servidores en la nube y elementos asociados como espacio de almacenaje) de manera muy sencilla. Puedes montarte tu propio centro de datos con 50 servidores en una tarde, si quieres. Y al día siguiente desmontarlo. La contrapartida es que es carillo, un poco la diferencia entre pillar un taxi o comprar un coche. Además, la nomenclatura de todo es ignota y confusa. Es complicadísimo además saber a priori cuanto dinero va a costar nada.
- Docker permite trabajar con contenedores, que son pequeños procesos autocontenidos, fáciles de ejecutar de forma estándar. Aunque la idea inicial que tienes al usarlos es que son un tipo de máquina virtual ligera, pero la forma más precisa de verlos es como procesos que tienen un sistema de ficheros para ellos solos. El trabajar con contenedores simplifica muchos problemas tradicionales de despliegues en producción, donde el control del entorno es crucial (y siempre daba problemas de algún u otro tipo)
- Kubernetes es la evolución de los containers, facilitando el usar múltiples a la vez y coordinándolos entre sí. Es ahora mismo un tema candente y de moda. Kubernetes no es la única opción, pero sí la que está ganando más atención. Utilizando Kubernetes y contenedores se puede abstraer los servicios del hardware en el que se ejecutan, separando la gestión del cluster (una colección de servidores, físicos o virtuales que aportan los recursos) de los servicios que operan sobre ellos. Todo esto es posible hacerse configurándolo en ficheros, así que cambiar la infraestructura lógica (qué servicios están desplegados y cómo se conectan entre sí) se convierte en un problema de cambiar unos ficheros de configuración, en lugar de gestionar servidores directamente y conectarlos.
Todas estas tecnologías tienen su curva de aprendizaje y necesitan tiempo para realmente entenderlos.
La verdad sea dicha, estoy enormemente satisfecho con estos últimos diez años… ¡Vamos a por la siguiente década!
Interviewed about microservices

I got interviewed about Microservice and talk a bit about my last book, Hands-on Docker for Microservices with Python.
I was an interesting view on what are the most important areas of Microservices and when migrating from Monolith architecture is a good idea. And also talking about related tools like Python, Docker or Kubernetes.
Check it the interview here.
Hands-On Docker for Microservices with Python Book

Last year I published a book, and I liked the experience, so I wrote another!

The book is called Hands-On Docker for Microservices with Python, and it goes through the different steps to move from a Monolith Architecture towards a Microservices one.
It is written from a very practical stand point, and aims to cover all the different elements involved. From the implementation of a single RESTful web microservice programmed in Python, containerise it in Docker, create a CI pipeline to ensure that the code is always high quality, and deploy it along with other Microservices in a Kubernetes cluster.
Most of the examples are to be run locally, but a chapter is included to create a Kubernetes cluster in the cloud using AWS services. There’s also other chapters dealing with production related issues, like observability or handling secrets.
Other than talking about technologies, like Python, Docker and Kubernetes; or techniques like Continuous Integration or GitOps; I also talk about the different challenges that teams and organisations face on the adoption of Microservices. And how to structure the work properly to reduce problems.
I think the book will be useful for people dealing with these problems, or thinking to make the move. Kubernetes, in particular, is a new tool, and there are not that many books dealing with it from a “start to finish” approach, looking at the whole software lifecycle, not only under a “I want to learn this piece of tech in isolation”.
Writing it also took a lot of time that I could be using in writing in this blog, I guess. Writing a book is a lot of hard work, but I’m proud of the result. I’m very excited to have it finally released!
You can check the book at Packt website and at Amazon. Let me know what do you think!
