
LLMs and Context
Let’s start for something simple. LLMs don’t have memory.
Every time that you make a call to an LLM, you need to provide as an input all the context related to the request. The LLM will pick up this context and produce a result.

But, when using AI tools, for example a chat bot, you see that you have a conversation. And it continues the conversation and references things said before. And that is because the chat bot itself maintains and references the context back and forth. In a naive way, it stores the conversation and sends it whole to the model for each question, making the LLM understand what was discussed before and continue when it left.
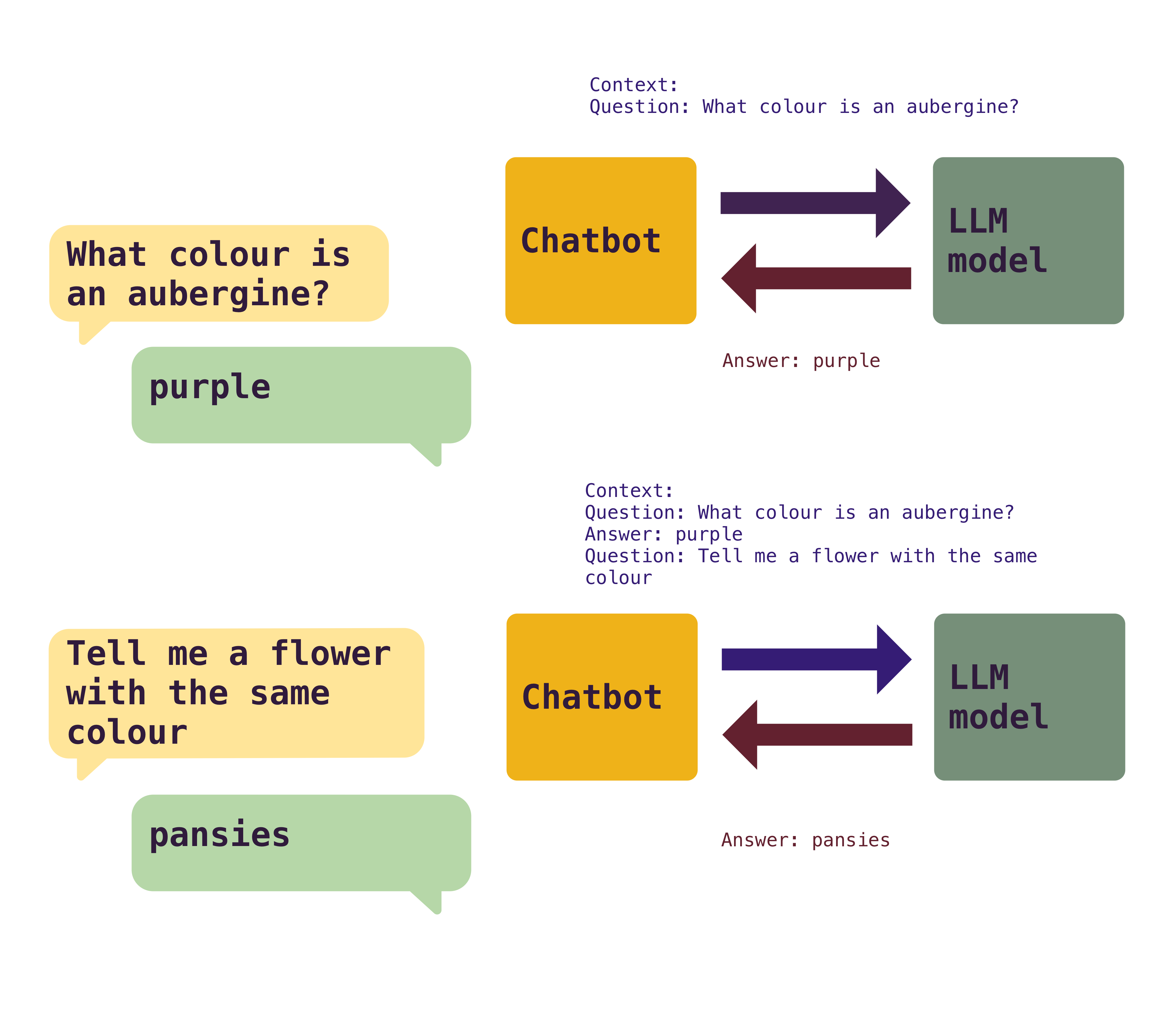
While the chatbot app itself can store the results, there’s a limitation in the part of the LLM on how much context can accept, which limits the length of a conversation. Currently the maximum context window in modern LLMs are around 200K tokens to 1M tokens, depending on model and price.
A token is a part of a word. You can make a round number and think that 1M tokens are about 750K words
While the context appears to be quite high, there are problems where it quickly adds up.
First of all, those numbers are the maximum context window, but not the effective one. Once you start getting over a few thousand words the quality of the responses can start to be affected. The model won’t pay attention to the whole context, but to the start and/or end of it, maybe missing important information in the middle.
Secondly, you can reach the effective limit quite quickly. You’ve probably seen that GenAI tools tend to return a lot of text. A very simple question can return 200 words or more. A complex one way more than that. Going back and forth in a conversation, or even worse, work on a project, can quickly get to 10K+ words faster than you think. Remember that each time you’re adding all the context that was generated before.
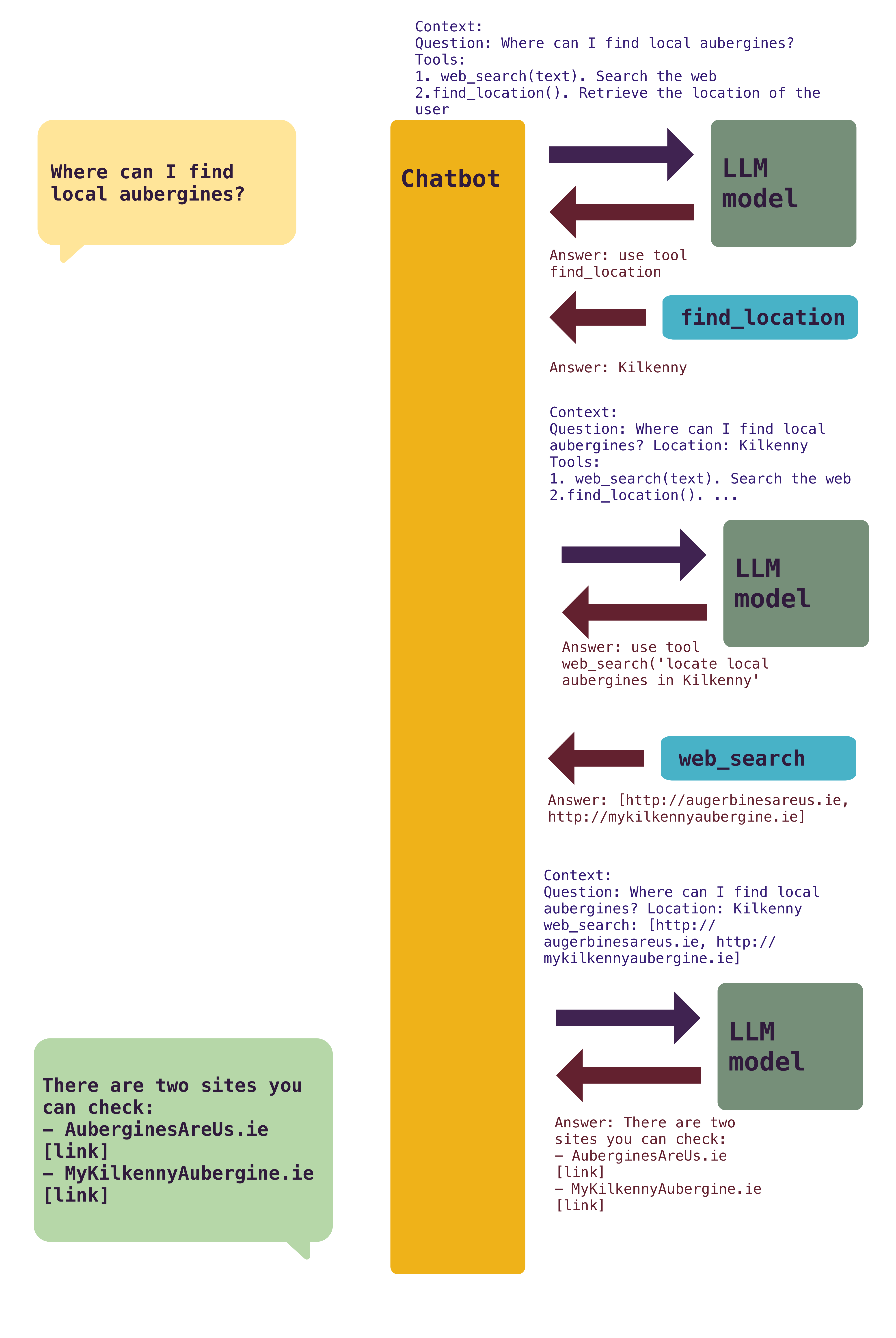
Third, your context is not just your questions. Everything that the model needs to know should be included in the context. That can be your preferences (e.g. please return always Python code by default and follow PEP8 conventions). If there are tools (what makes agent capable of producing results), they need to be added to each individual request. And each tool needs to describe what is capable of doing so the model can request its usage.
The calls add up quickly. The context grows bigger.
Managing the context becomes an important part of handling any AI tool. There are a few ideas that can be used:
- Compress elements. Reducing the amount of information that’s necessary for describing tools, for example.
- Drops parts of the context. You can explicitly avoid storing parts of the conversation if they are not relevant any more, or including them dynamically.
- Summarise the previous conversation. To keep the whole context, you can ask the LLM model to make a short summary and use that in the newer calls. LLMs are good summarising!
- Chunk the information. Instead of one big call, doing smaller ones with defined task. This is the idea behind doing a plan first (big call) and then following up (run each task independently with a smaller context)
- Avoid including all tools. Instead, dynamically add tools as they are used or requested by the LLM. Tool management is tricky, as each one makes the AI system more capable, but at the same time, consumes important context.
MCPs in particular tend to provide many tools, like 50 per MCP. Having many MCP tools available all the time is not optimal. They quickly occupy the context!
If you develop an agent, which is a loop talking with an LLM, you need to ensure that your context is always healthy for the best results, which makes the management of the context very important.
Managing the context is not only important for getting good results, but also to keep costs under control. Cost is determined by amount of tokens sent to the LLM model. Unless the model is local or in your own controlled hardware, each individual call to the LLM is costing money, and it’s more expensive the more context you add. You can imagine that with complex operations, or agents performing operations for a long time, your bill can grow quickly.
Even if you use a chatbot tool, like ChatGPT, knowing how the context works will help you to better use it and to avoid overwhelm it with too much context.
