
Interacting with GenAI Models
While working with AI is still something relatively new, there seems to be a developing pattern of openness and interconnectivity that’s very interesting. Especially since that seems to go against the latest trends in technology and reminds me of the initial promise of the Web.
We are detaching GenAI Models from the frontend that allows us to interact with them. Let me explain.
When ChatGPT was released, the only way to interact with the model was with through OpenAI application. You wrote in a chatbox in ChatGPT web and receive a response from an OpenAI model. But then shortly we started having more OpenAI models available (chat with GPT-3, GPT-4, o3-mini… so many of them)
But other companies released their own models (Arthropic with Claude, Google with Gemini, Meta with Llama, etc), and at the same time tools enriching the connection with models were developed, mostly IDEs (Cursor, Windsurf, etc). No longer it was a pure chatbox, but these “frontends” managed the information that was provided to the Model itself.

The different tools also became possible to work in Agentic mode, where they interact with the model out of a request/response paradigm, but where the model produces a plan and then calls itself multiple times to proceed with it. All that with interaction from the “frontend” that allows to read/write files, provide settings, etc.
On advance to this, the models can be executed in different ways.
- When you get a paying account with your IDE, you get some allowance to use in models where the IDE company has reached some deal. For example, a Cursor account allows you to execute models like Claude, Gemini Pro and GPT. Extra usage will require you to pay extra. Windsurf works with the same model1.
- You can execute open source models locally using something like Ollama. Your computer may not be capable to run big models, but it’s a possibility!2 No paying in this case, you’re providing the hardware and electricity.
- Directly with API keys from the companies providing the models. E.g. an OpenAI API key for running
o3. This option is available for most premium models in most tools. - With a Cloud provider that allows you to execute models in their servers. This is similar to execute them in your local computer, but in a “rented computer” in the Cloud. For example, AWS Bedrock allows you to execute a big list of models charging you for each of them.
Most projects allow you to pick and choose how do you want to work3. For example, Zed is an open-source code editor that allow you to use all the previous options, including paying them for an account. Aider is a command line tool that is purely open-software and will require you to configure the LLM model to connect to.
All this makes a lot of different combinations. But more importantly, it creates an ecosystem where both elements (frontend and backend) risk being commoditised to certain degree.
Backend Models
It is very easy to change one model for other, even between the same sequence of actions. If there’s a new release (let’s say that Claude 4 is released), swapping to it it’s almost instant. But not only from models of the same company, but from different companies as well. At the moment there’s a lot of activity with new models, and there’s very little moat created that makes OpenAI to retain people if Anthropic releases a new models or vice versa.
Models are extremely expensive to produce and advance. But at the moment there’s a significant group of companies working very hard on them. There’s significant advances done in all of them, and it seems like who’ll win is still unknown.
Even though there is the concept of specialised models (e.g. models for healthcare, laws, etc), they are based on the general models created by companies like OpenAI, Meta or Google. Creating a cutting-edge model is not an easy task, but we live in a world where we have, so far, competition. Of course, the objective of this companies is to be in a “winner takes all” scenario, where they can outpace their competitors and capture all the market, but I’m not that sure that we will get to there.
As a comparison, we can compare it with the situation with search in the early 2000s. Google was much better than the rest of companies like Altavista, Yahoo or Lycos. That was pretty obvious to everyone. Google kept improving, the users moved to use it, and captured all the search market for 25 years4.
But, so far, the difference so far is not completely obvious. Most of the models are quite capable! There can be small differences between models, but there’s no one clear winner so far. OpenAI has the brand recognition so far, which is an important head start, but we are still in early days, and, for example, for programming tasks the one in the lead appears to be Anthropic with their Claude models.
Given on how expensive is to create a model, there’s the chance that some company just goes bankrupt. But, in that case, there’s the chance that they’ll go out in a constructive way and open source their models, in the same way that Netscape created the Mozilla project. If that model is powerful enough, it may provide an alternative to proprietary models, which may drive down the opportunity for the winner to capture the market.5
Another detail here. There’s a lot of chat about the position of Apple in the market. Given how models work, it is entirely possible that they can capitalise a lot on allowing to connect to other models behind the scenes, making their operating systems working effectively as a frontend. This is unlikely6, but possible. On the other hand, in the long term, I think they are capable of reaching their own model and use it exclusively in their products. Just because they are two years late to the party doesn’t mean that they can’t win. They have a huge attachment factor on their iPhones and MacBooks. I think they are in a good position to take advantage of that in the long run.
Frontend Tools
Perhaps there’s a bit more on the frontend front, where people may choose their favourite editor/IDE and become adjusted to them. After all, we historically had our editor wars where people preferred Vim to Emacs or IntelliJ is a viable product even if there are free alternatives. But the main contenders at the moment are VS Code forks, and the Agentic mode makes less important the interface itself, as it is essentially a chat box where you describe the changes that you want to do and the agent itself will do them.
It is very likely that there’ll be open-source alternatives that will cover most of the use cases7, making difficult to really differentiate or create a massive product8. Interestingly, I think there’s a real opportunity into the review part of the process. Make good tools to see the difference with the changes the agent has done, and help summarising and understanding them. So far I don’t think that the work there is stellar, just adequate.
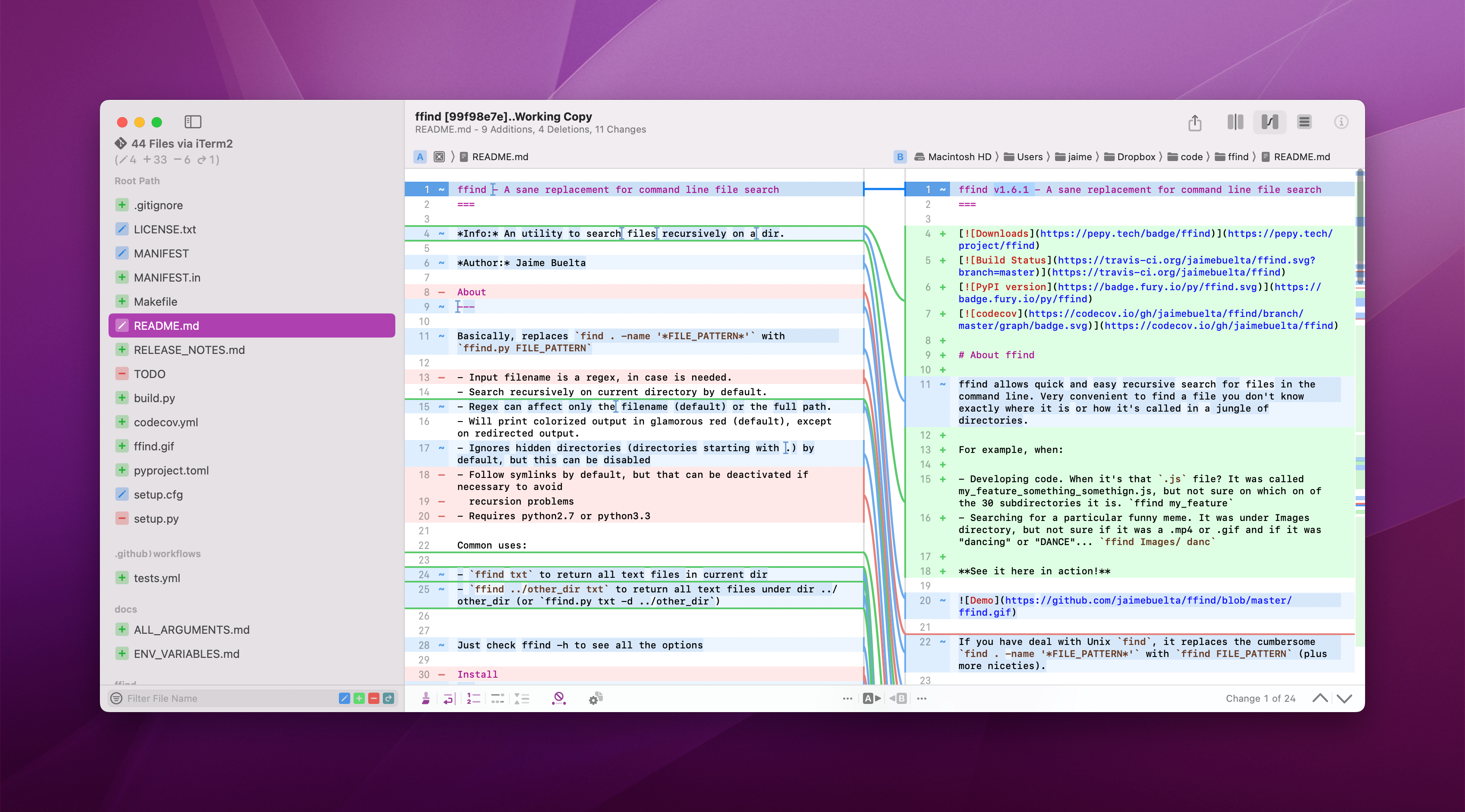
Another element is the integration with MCP servers. MCP is an interface that, in essence, allows an agent to connect to an API and interact the model with them. The API could be a local API or a remote call. Any kind of connection, really. The MCP gives an entry point to the API, including credentials, and a standard way to understand the available APIs for the agent.
For example, you can connect to a local database and create natural language queries that will be translated, through the MCP request to the database. The agent will be able to perform several actions, poking and analysing the MCP to discover their capabilities9.
If there are more than one MCP, the agent will be able to correlate information between the sources. This is an extremely powerful capability. For example, you can use an agent connected to Jira and GitHub and ask the agent to find tickets included in a GitHub release and label them in Jira properly. All this with a natural language request!10
This is now a standard on any tool, and it doesn’t present a differentiation for the frontend tools. It is also likely that many interesting features will be created independently through MCP servers, instead of by the tools’ team.
Summary

All the GenAI are at the moment is incredibly in flux, and it’s very difficult to know what’s going to happen next. I’m guessing this post will get older very soon, but so far my view on this is:
- You can think of GenAI as composed on one frontend (the tool you interact with) and a backend (the model that provides the GenAI capabilities)
- Both ends are pretty combinable. And both risk to be commoditised.
- Backends (models) are extremely expensive to create and to run. There are multiple companies investing ridiculous amounts of money on them at the moment, and there’s no clear moat or indication that we will be in a winner-takes-all scenario.
- Frontends (tools like agents, IDEs, chatboxes, etc) are capable of interacting with the models, and most interesting features may be in interaction with other services through MCPs or other interfaces. There are already capable open-source projects, and agents are moving to be less hands-on.
- Today, working with code, it’s still important to review the generated code. There’s a shift from writing code to reviewing code that may cause a shift in features or tools.
- Agents are capable of connecting and correlating to multiple sources through MCP.
- I use agents that are more thought to operate with code, but I think this is almost ready to move up in the chain to produce local apps more oriented to managers or PMs. Probably there already exist. So far I don’t think that the ChatGPT app allows to connect through MCP natively.
This kind of structures and interoperability reminds me of the early days of the Web. Not sure if it will pan out in the same way, there’s also the possibility that we end up with yet-another massive monopoly/oligarchy. Which was also how the Web ended up being in the end.
- Normally these IDEs will have some free account with a small allowance to allow testing ↩︎
- Plus, you may have a massive computer on your desk ↩︎
- Within a range of options available, of course ↩︎
- There’s one key element, the fact that the search market was free. There was no transition costs from searching from Altavista to Google. With the current models, they all have a cost associated. There could be business deals that make more difficult to move from OpenAI to Claude for companies. I wouldn’t rule this factor as a possibility, in the way that Teams is a very successful “inferior” product over Slack due Microsoft pushing it as part of other deals. ↩︎
- Again, the main difference with the early days of the Internet is that browsers were free. Models are extremely expensive so far to operate. ↩︎
- Apple is a control freak and they don’t seem to like to use a model that is not up to their standards ↩︎
- As we’ve seen, Zed covers most of the features of Cursor, for example. It’s even a bit more flexible in how to set up the backend model to use. ↩︎
- I think it will be totally possible to do a niche product, or even a popular one, but right now it seems that success is more measured in creating N billion dollar products, which is an extremely high bar. ↩︎
- I have to say this feels magical. You just connect the MCP and ask the agent to use it. The agent will start figuring out how to use the API ↩︎
- A use that I found out is to replace the native search in Confluence. Confluence search is, ahem, not great. But if I connect through an agent and ask it to search for something (e.g. “find me the latest updated documentation about X”), it will figure it out producing better results than me searching directly in the web interface. ↩︎
