80 chars per line is great
Probably the most controversial part of PEP 8 is the limit of 80 characters per line. Well, is actually 79 chars, but I’ll use 80 chars because is a round number and the way everybody referes to it.

Capture all the experience
There are a lot of companies where the standard seems to be “PEP8, except for the 80 chars line restriction”. On GitHub projects, which in general follow PEP8 (it seems to be a very strong consensus), that’s typically not found. In explicit code guidelines, the restriction could be increased (100, 120) or even removed at all. The usual reason for that is stating that we are not programming in VT100 terminals any more, and we have big, high-resolution screens. This is true, but I’ve found that that limitation, combined with the use of whitespace in Python, makes the code much more compact and readable.
It seems that, naturally, Python code tends to occupy around 35-60 characters (without indentation). Longer lines than that are much less frequent. Having suddenly a line much longer than the rest feels strange and somehow ugly. Also, having the mandatory indentation whitespace increase the line width is a good visual way of minimising the nested loops in your code and suggesting, in a subtle way, to refactor anything that is indented more than about four times.
For example, compare this:
def search(directory, file_pattern, path_match,
follow_symlinks=True, output=True, colored=True):
''' Search the files matching the pattern. The files will be returned, and can be optionally printed '''
pattern = re.compile(file_pattern)
results = []
for root, sub_folders, files in os.walk(directory, followlinks=follow_symlinks):
# Ignore hidden directories
if '/.' in root:
continue
# Search in files and subfolders
for filename in files + sub_folders:
full_filename = os.path.join(root, filename)
to_match = full_filename if path_match else filename
match = re.search(pattern, to_match)
if match:
# Split the match to be able to colorize it
# prefix, matched_pattern, sufix
smatch = [to_match[:match.start()], to_match[match.start(): match.end()], to_match[match.end():]]
if not path_match:
# Add the fullpath to the prefix
smatch[0] = os.path.join(root, smatch[0])
if output:
print_match(smatch, colored)
results.append(full_filename)
return results
with this:
def search(directory, file_pattern, path_match,
follow_symlinks=True, output=True, colored=True):
''' Search the files matching the pattern.
The files will be returned, and can be optionally printed '''
pattern = re.compile(file_pattern)
results = []
for root, sub_folders, files in os.walk(directory,
followlinks=follow_symlinks):
# Ignore hidden directories
if '/.' in root:
continue
# Search in files and subfolders
for filename in files + sub_folders:
full_filename = os.path.join(root, filename)
to_match = full_filename if path_match else filename
match = re.search(pattern, to_match)
if match:
# Split the match to be able to colorize it
# prefix, matched_pattern, sufix
smatch = [to_match[:match.start()],
to_match[match.start(): match.end()],
to_match[match.end():]]
if not path_match:
# Add the fullpath to the prefix
smatch[0] = os.path.join(root, smatch[0])
if output:
print_match(smatch, colored)
results.append(full_filename)
return results
In the first code, there is some scrolling, but even when presented in without scroll, the code looks uglier, as it does not look visually balanced. The second code seems nicer to me and I can read it easier.
Another important part is that I can display more code in the same space. There are tons of time that you need to keep an eye to different parts of the code, in the same file or in a different one. My favourite way of doing that is displaying them side-by-side in columns. Having a limit of 80 chars on the whole file, that gets nicely rendered and I don’t have to worry about lines displayed not being lines in code or configure editors. I al so makes that if I open vim for a quick fix on a terminal, I don’t have to worry much about the size. I can focus on the code.
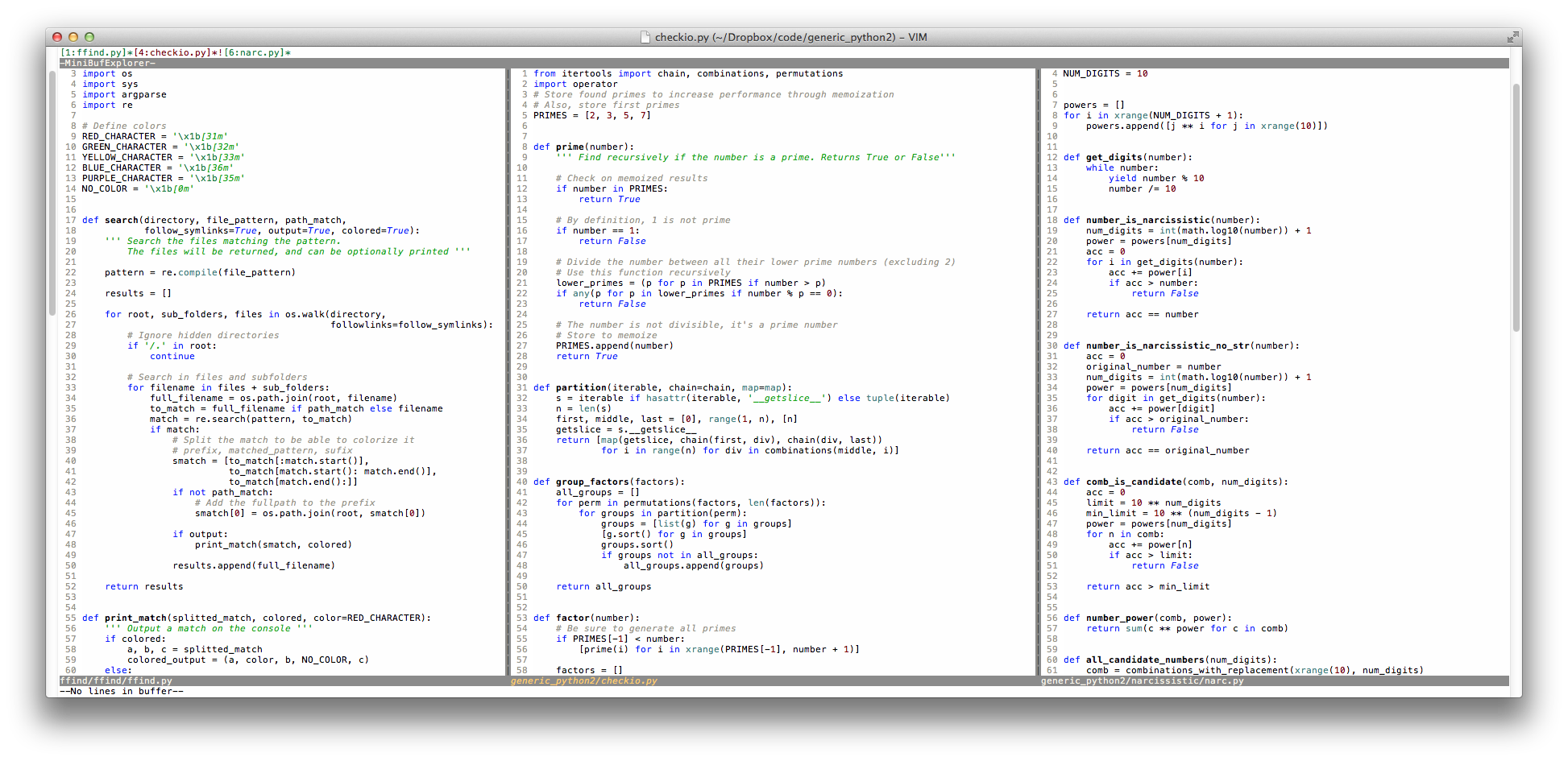
There is still room for one more column!
My only problem with this is Django. While using Django you have to use a lot of this kind of calls:
ThisIsMyModel.objects.find(field1=value1, field2=value2).count()
In case of indented code, the ‘bare minimum’ of calling a model function could leave you with very few available space… I still apply the same principes, and try my best to render the code in a way that in clear and readable, but it’s more difficult that with other Python code.
So, even if the initial intention probably has little to do with all those things, I really feel that this limitation helps me writing more readable and compact code. I am sort of a “readability” integrist, in the way that I feel that readability in the code is the most important consideration by default, and should be keeping in mind at all times.
What do you think? Do you like the 80 chars limitation?
UPDATE: There is some discussion on Hacker News, in case you want to check there.
UPDATE: After a comment, I’ve released my colour scheme in GitHub. In case anyone is interested, here it is. It’s called “Jaime” just because I already had that as the name of the file.

I have been just wondering why code editors cannot implement smart line wrapping? After all, this is not 80s and pico anymore and we have RAM and CPU power to do a simple heurestic line wrap. Doing manual wraps sounds kind of stupid, because line wrapping is just a simple task computer can do and we are freaking programming those computers to work for us.
I’d find extremely annoying if an editor will automatically change a line I’m writing at that moment. Most of editor I’ve used (I’m mostly a vim user these days, but I’ve used other previously) will help you when you hit the “enter” key, properly formatting the new line (indentation, etc)
Another possibility is waiting until you write and then fix the lines, or when finishing a function/paragraph. There are several tools that can help with that (like autopep8), but you’re right that it seems not to be an option out-of-the-box.
May be it was not about automated changes in your code but about displaying code with different line breaks than real, like “word wrap” in notepad-like editors but respecting syntax. So someone can write code with 120 characters limit and somebody other can read it with 80 characters limit.
That’s a very interesting idea. Some sort of “syntax reformat”. But I’m not sure if that will be practical, as there should be one “canonical” way for the code.
I guess that in practice implementing it in a safe and convenient way can be extremely difficult.
ugh really. This is like the segway of editor features. Its a solution in search of a problem. If you are streaming off the edge of the abyss on your 4th level of nested list comprehension its probably time to re-evaluate what you are doing.
In regards to your statement about Django – you can break up that or similar statements like this: http://pastebin.com/raw.php?i=sSswBdSA
Obviously my example is ugly, but you get the concept.
Mmmm, I find slashes at the end of lines really really ugly and avoid them as much as possible, but it is an option
PEP8 actually recommends using line continuations instead of backslashes at the ends of lines. It’s less fragile and much more pleasing to the eye.
Example: http://pastebin.com/c0FS2vjF or http://pastebin.com/wLEx1j8j
You could of course break the line in between the already present parenthesis instead: http://pastebin.com/c0FS2vjF
Na, use the brackets Luke
http://pastebin.com/raw.php?i=tW0uDnxc
I have Sublime Text set up to show a vertical ruled line at column 80, but have word wrapping itself turned off. I use this as a guide – I try and keep all lines under this width, but if they occasionally go over it’s a flag to refactor that line later. I suppose I think of it as another linting step.
I also adhere to the rule you mentioned – “refactor anything that is indented more than about four times.” I find this particularly handy in Javascript where nested event callbacks can get complex.
I wholeheartedly agree with you Jaime. In the beginning I used to create horribly long lines of code but after a few months of writing Python – I saw the error of my ways and while I still have a long way to go, I definitely now write lines with <= 80 characters per line.
This makes my code much easier to read and grasp, plus it forces the code to be concise and to tackle problems in a laser guided fashion rather than "let me throw as much code at this as I can".
Great post!
Thanks!
This is fantastic, thanks for writing!
Thanks!
I just do this with long queries http://paste.ubuntu.com/5646538/ Much more readable “filter by line” thing.
Mmmm, interesting, I’ve never though that you could make that trick. I’ll keep it in mind. Thanks!
>It seems that, naturally, Python code tends to occupy around 35-60 characters (without indentation).
Thats completely irrelevant for a language that requires indentation to work, specially when one insists in using multiple hard-coded spaces for each indentation level.
It doesn’t matter if you use tabs or spaces, they both use space on the screen, which is what’s relevant for readability.
Except for Python, I normally have used tabs and set them to display at 2 spaces. Because of Python, I have tried to migrate to 4 space characters per indentation in other languages as a matter of conforming to others’ standards, but it is a nuisance, especially if I have to indent below a line which itself requires continuations to fit on the screen.
`:set colorcolumn=79` and use it … the html thing is def and issue though (erb, .mustache, jsp, whatever your template choice is). i just break lines on attributes
Yes, I use that. Well, a variation, to show that as an error, but it’s the same idea.
From my .vimrc
It isn’t “80” because of VT100s. VT100s are 80 because IBM *punched cards* were 80 columns. Yes! You’re constrained by a convention dating from … 1928. Actually, in FORTRAN, the limit was 72 columns, because the last 8 were ignored, and often used for a card sequence number, in case the deck was dropped (there were card sorters). (The first six columns were also reserved for other things, so in the end it was 66 columns of program code.)
Well, I am not arguing from when / where that limitation came (I know it was from IBM punched cards, by the way). I am just saying that it sort of make sense, as I feel it makes the code readable.
It is also the same idea behind books and newspapers displaying the text in columns.
I am showing a VT-100 because it’s a nice looking piece of hardware. And it could also use a 132 column setting… 😛
I’m sorry. My complaint was mainly directed at the choice of exact numbers in PEP 8, I suspect, and I wanted to emphasise that these numbers really are a second or third derivative from obsolete technology (card punches for 80, or line printers for 132 columns), and thus an arbitrarily odd choice for a 21st century programming standard.
I agree that very long lines of code can be harder to read, as you say.
Told you so James
Pingback: 80 chars per line is great (Python related) | My Daily Feeds
At which font size ? Which screen resolution ? How many Pixels per Inch ?
I use Menlo 11 points in an iMac 27” (that’s 2560×1440, 94 ppi), but I find also comfortable to use the same setting on a Macbook Pro.
This is a classic among code wars. Me, as a Django developer, I began following the 79 rule, but since I switched to longer lines, my code is much more sane. And, anyway, Django community does not follow the 79 chars per line either:
https://docs.djangoproject.com/en/dev/internals/contributing/writing-code/coding-style/
“One big exception to PEP 8 is our preference of longer line lengths. We’re well into the 21st Century, and we have high-resolution computer screens that can fit way more than 79 characters on a screen. Don’t limit lines of code to 79 characters if it means the code looks significantly uglier or is harder to read.”
Yes, as I stated, the long names in Django makes difficult to keep lines to 80 chars without looking weird.
I still anyway try to fit it, but I get your point…
Yes, I stick religiously to 80 char limit for ALL programming languages I do. Shorter lines encourage writing code with lower cyclomatic complexity, overall more readable code, and the point of larger screen is not to start writing lines 360 chars wide (which is what I can do on my 30” screen), but to be able to open 4 files side by side.
Nice writeup! (and kudos for the emacs frame! ☺ )
You could add a big reason for using multiple windows: Doing a 3-way merge.
If you ever tried doing a clean merge with code which has 200-character lines, you’ll know to avoid long lines.
Thanks. The frame is actually Vim (MacVim) 😉
Yes, 3 ways merges can get nasty if the lines are long…
I saw the vim name only after sending – a cultist disguise! 😉
Let’s say is Vim in disguise!
I disabled the 80 char warning in my emacs (checked via Flymake), because having red-marked lines hurts, and there are sometimes reasons to break the 80 char rule. 80 chars are important, but readability is not a single-parameter function.
Yup, I personally do like the 80 chars limitation and try to write code that conforms. Django’s models.py is an exception, just like you noted, but generally lines of code should be way shorter.
Try to have the docstrings at 60 chars per column (still 80 chars per column on code). Should look nicer. 😀
Hail the 80 chars rule!
Where it really matters: Github.com
Their source code display is in a width limited box and it’s a pain there to have to scroll sideways.
set tw=79
^Setting textwidth in vim will auto wrap the line when you exceed 79 chars.
Combined with autoindent, I find it works quite well.
Also when editing older code where the author didn’t enforce this (and you don’t have to follow his style — if the code will be merged upstream, please respect whatever style the author chose), I like to use ‘gqap’ .. although the result can be awful depending on the spacing, as it acts on a whole paragraph
Does it matter ? It’s an old question but which seems definitivly unsolved, as if reading was neither desirable nor usefull.
Few years ago I published a small tool for nice code listing [for C, PyThon and VHDL – URL below] with cross references.
I still use it before travelling when some bugs still bother me : I take a pen, a rubber and a source listing. A different atmosphere, a small constrained place where I can only move my eyes and my fingers, and I see my source code very differently.
Give me 80 chars per line or GIVE ME DEATH
Back in the ’80s I worked on a helped test out a system that limited the software writer to one screen for each procedure, which was probably less than 80 characters and no more than 25 high.
I love the 80 (79) character line, exactly for the same reason you mentioned… displaying more code.
wow a lot of comments.. just couldn’t read all…
I can resume this in code readability and code maintenance…
We all already know that verbose names are easier to read.. and that have a lot of benefices (in terms of less tired developers and no need to experts than can understand no verbose code…
Example:
if ( x != y) { list1.Add(x); }vs
if (studentNew != studenOld) { listOfNewStudent.Add(studentNew); }but yes this kind of code add numbers to the lines.. then is our decision to where to wrap to make it readable!!!!
(extremes are often bad…) We must aim for readability!.. indentation, verbose, lamdas.. all this helps, but we must understand when it becomes worst.. and for me is very simple.. if I’m writing code.. and I can’t event easily read my how code.. something is wrong
What Vim colorscheme are you using? 🙂
I am using my own color scheme. I heavily modified some other scheme, so I’ve uploaded it to GitHub, in case someone likes it…
https://github.com/jaimebuelta/jaime-vim-colorscheme
It wasn’t uploaded correctly. The jaime.vim is a link to your local version. 🙂
Ok, now it should work. Sorry about that, I was trying to be too clever with symbolic links 😉
80 characters per line was fine when the language limited variable names to a max of 8 characters, and object-oriented programming wasn’t invented, yet. My biggest reason for limiting the length of lines is that I occasionally print code on pages that I tape together so that I can fully see and manually diagram code for better understanding, and this always works better with shorter lines.
Couldn’t agree more with this post. I argue these exact same points quite often. The only real push back I get is with long strings of text (e.g. error messages, end user descriptions, etc). I usually just throw these in parens and use the line continuation. If I need to make a big edit, just use the power of the editor to splice and dice.
I think a distinction is useful between ‘real’ code and embedded prose, string literals etc. Excessive line length caused by too much code indentation definitely shouts ‘refactor me’ – and something less than 80 characters would be useful here.
But when it comes to long string literals (where the desired result is semantically a single line (e.g. an error message which will be word wrapped at a later point in the UI – so triple-quoting isn’t helpful), I think all the alternatives for breaking lines artificially are worse than the (long-line) alternative. The ambiguity of *where* to put a non-semantic line break, and whether to reflow things if the text changes, the lack of obviousness when reading the code about whether the string is semantically a single line, as well as the number of bugs I’ve seen where commas have been incorrectly added – assuming that a implicitly joined set of strings should actually be a list…
Perhaps this all just means that such string literals shouldn’t be in code in the first place.
I agree that we need a limit, but in my experience 80 characters is often too limiting and sometimes causes wraps that make the code *less readable* instead of more readable.
I use a vim colorcolumn at 80 characters as a soft limit, but the hard limit for my projects is at 100 (or 99, to be exact). This has proven to be a nice guideline to write readable code, versus the 80 hardlimit that forces you to write short code (which sometimes is less readable than a clean & clear line with 90 characters).
Pingback: 80 chars per line is great | Python-es | Scoop.it
Pingback: 为什么编码规范里要求每行代码不超过80个字符的限制是合理的 | 微传媒中国
Pingback: 为什么编码规范里要求每行代码不超过80个字符的限制是合理的 | 艾艾时代
Pingback: 为什么编码规范里要求每行代码不超过80个字符 _ 移动互联网 _ HTML5工作室
Shorter lines are easier to read.
That is why newspaper columns are so narrow. (But of course I’m not suggesting a limit less than 80 chars!)
Pingback: 为何编码规范每行代码不超过80个字符是合理的 - 算法网