
Great female participation on PyCon US 2013

This picture is AMAZING
I have read that around 20% of PyCon attendees were women. I’m sure I’ve seen it on more places I can’t find at the moment, but is at least here.
This is fantastic news, a great success for the PyCon, the Python community, and specially groups like PyLadies and Lady Coders. The opening statements of Jesse Nollan is a must see.
As I have previously expressed some concerns in this blog about whether requiring a Code of Conduct is the best approach, I’d like to say that I was wrong and it seems that had a positive impact. The CoC is also currently under review, and I’m sure it will be improved. It has also been used with great care, as the PyCon blog shows, which is also something to kudos.
There has also been special programming tracks for kids, which is awesome.
Of course, that is not the end of the road, and there is still much to do, but it is very encouraging. Keep on the good track!
Say NO to web pages adapted to iOS
 I really really don’t understand why there are people that think it’s “better” to replace a perfectly good web look and feel for a stupid “adaptation” to iOS with sliding pages and different layout.
I really really don’t understand why there are people that think it’s “better” to replace a perfectly good web look and feel for a stupid “adaptation” to iOS with sliding pages and different layout.
I mean, c’mon, If your page does not have a good design to start with, why not changing that? For both web clients and iOS devices. I remember when there the wordpress plugin for iOS was activated by default and all the blogs changed totally their appearance for a kind of “magazine” that, yes it looked good, but was much more difficult to read.
I get to have a responsive design to adapt the web to some sizes (like a mobile device), but changing fundamentally how your site looks and is designed is totally pointless…
There is one thing that is even worse. Apps that wraps a web site, removing all the functionality of the web browser for a stupid and independent, limited app. And even worse, they will constantly will bother you with reminders to download and install a pointless app.
No, just don’t. It is totally stupid. Work on your web page, get a great design, and make easy for the people wanting to read it, well, easy. After all they’re the ones interested in you….
PD: I think the Android ecosystem is similar. The same applies.
Google Reader as a “Be careful with the cloud” tale.
![]() I have been hit by the recent “readerpocalipse”. I use Google Reader daily heavily, and it is THE main access I use to consume information on Internet. I am taking a look at alternatives, and I (and everyone else that used it heavily) will survive. But I am worried about what impact can this have in the perception and operations of cloud services, specially by Google, but also in general.
I have been hit by the recent “readerpocalipse”. I use Google Reader daily heavily, and it is THE main access I use to consume information on Internet. I am taking a look at alternatives, and I (and everyone else that used it heavily) will survive. But I am worried about what impact can this have in the perception and operations of cloud services, specially by Google, but also in general.
During the last years, we have seen a lot of cloud services that the perception has been “this is going to be available forever”. Of course, we knew that it was not necessarily the case, something catastrophic can happen, like the company going out of business. But, in general, if it was from a big, profitable and established company (like Google) and it has a critical mass of followers, the feeling was that maybe it was not going to be upgraded, or could have availability problems, but it will be still there. We awake yesterday in a different scenario.
This is going to make me change my perception of cloud services. From now on, I’ll add an extra care when choosing a service, and that will probably make me use them less that I was doing it before. Specially if I start using it a lot, I’ll try to evaluate more seriously plan B’s and ‘what ifs’. Probably that’s a good thing, as I was probably being a little naïve about all this. I was keeping some minimum backups “just in case”, but I will now probably take everything more seriously and try to store less things in “the cloud”.
Internet y el fetichismo de los números
Una cosa que no he entendido muy bien de la “cultura internetera” es esa reivindicación tan fuerte de los “followers”, los “likes” y la difusión mal entendida.

Y de todos, todos los colores
Vale, en cierta medida, si tu blog lo siguen 10.000 y no 10, llega a más gente y (se supone), es más interesante. Sin embargo, especialmente en España, se llega a casos ridículos al querer utilizar los números como arma arrojadiza ante cualquier situación… O, al menos, se justifica todo a través de ello…
¿Que no me gusta lo que has dicho en Twitter? Hago un unfollow que además lo canto a los cuatro vientos: “¡Eh! Que te fastidias que tu contador de seguidores baja, eh, ¡que lo sepas!”
¿Que te peleas con alguien? Sacas a colación el número de seguidores, las visitas a tu página web o el número de reproducciones de un vídeo.
Por no hablar de compañias que “venden” seguidores, tanto en Facebook como en Twitter. ¿Qué valor tiene un seguidor comprado?
Un caso claro es el hecho de mandar todo a Menéame, a pesar de que tus anteriores artículos los hayan puesto a caldo. El caso es que te lea gente, aunque sea una audiencia totalmente distinta a la que (en principio) debería ser tu target… Sinceramente, la audiencia media de Menéame (y otros sitios por el estilo) está tan llena de trolls, que yo nunca pienso que merezca la pena enviar nada, y mucho menos promocionarlo activamente, como hace mucha gente.
Creo que estamos locos. Nos estamos dejando llevar por querer ver “quién la tiene más larga” y no por “quién está más satisfecho con sus relaciones”. El número de seguidores / lectores de tu blog / etc es el tamaño de tu audiencia, pero es mucho más importante la CALIDAD de esa audiencia… Que nos olvidamos de que una visita, sin más, no implica nada. Puede ser alguien a quien no le aportas absolutamente nada (y, por tanto, irrelevante), o, en el peor de los casos, alguien que te pone a caldo sin motivo…. Especialmente si no vendes nada, como suele ser el caso (aunque, incluso si vendes, el hecho de que las visitas que tengas sean “de calidad” puede ser muy importante para tus conversiones)
Algo de promoción con cabeza no está de más, y es necesario. Pero creo que estamos sacando todo de madre y nos estamos poniendo el énfasis en el lado equivocado de las cosas.
GitHub for reviewing code
A couple of weeks ago we started (in my current job) to use GitHub internally for our projects. We were already using git, so it sort of make sense to use GitHub, as it is very widespread and used in the community. I had used GitHub before, but only as a remote repository and to get code, but without much interaction with the “GitHub extra features”. I must say, I was excited about using it, as I though that it will be a good step forward in making the code more visible and adding some cool features.
One of the main uses we have for GitHub is using it for code reviews. In DemonWare we peer-review all the code, which really improves the quality of the code. Of course, peer-review is different from reviewing the code in an open software situation, as it is done more often and I suspect than the average number of reviewers is lower in most open source projects. We were using Rietveld, which is a good tool, but probably not stellar when you start using it. The main process was, write code, submit it to Rietveld, ask for reviewers, check and discuss comments, update the code and repeat the process; and wait for approval for the reviewers to submit the code to the remote repo.
What can I say? I am quite disappointed with the result. It seems that the tools for code review in GitHub are not great, to put it lightly. Not great at all.
I guess that my disappointment is big because I though that, as GitHub is so used in the open source community, the review tools should be very good, as open source is all about checking and reviewing code that anyone can send. But the fact is that the review tool itself is pretty limited.
Narcissistic numbers
Here is a nice mathematical exercise from Programming Praxis. Is about finding the “narcissistic numbers”, n digit numbers numbers where the sum of all the nth power of their digits is equal to the number.
To reduce the problem a little, I decided to start by limiting the number of digits. So, the first approach will be just calculate if a number is narcissistic of not. So, after checking it and making a couple of performance adjustments, the code is as follows…
Thoughts on Code of Conducts
I’ve just read this statement from the PSF about requiring a Code of Conduct, and I felt somehow a little down.
Don’t get me wrong, I don’t think that a CoC is something bad, and everything it says (at least the referenced PyCon US one and the example in geekfeminism.com) makes sense. It’s just that needing a CoC feels a little … formal.
I don’t like very much formality, as I like to think that PyCon conferences are more a bunch of somehow friends getting together and sharing knowledge. I’ve always felt very welcomed in the Python community here in Ireland, and the atmosphere in PyCon IE (and other meetings) is absolutely fantastic. I haven’t seen anything that I will consider remotely discriminatory (like I saw back on my college years, for example). I’ve always imagined that the rest of the Python conferences and communities have the same “magic”.
Of course, I am seeing this from my particular, mainstream european-male point of view. I am a foreigner here in Ireland, but less say on “close, european orbit”. I’m not sure if some of the problems that the CoC tries to avoid are present and I am just not noticing. I’d like to think that’s not the case.
I don’t know, makes me think about what is the general perception and behaviour of the development community. I know there is discussion out there about wether the geek population is welcoming to diversity or just a bunch of jerks that just can’t behave (and all the spectrum in between). I guess it just makes me sad to think that we may need “an adult” telling us not to say things that we already know that we shouldn’t. It’s 2012, we have no excuse.
As I say, I just feel a little… disappointed. Like thinking that there is something wrong in all that, that we are grow up and that things are not on the same level of friendly informality. That we need rules to ensure everyone feels safe. I guess that a small number of spoiled brats that can’t behave like adults and are just ruining the party to everyone else. 😦
In defense of resting
I have been watching recently some documentaries about software development, including the classic Triumph of the nerds (available in YouTube in three episodes, 1, 2 and 3) and Indie Game: The Movie. They are both very good and I’d recommend them not only to developers, but to people interested in technology and/or entrepreneurship in general.
But they are very good exponents into something very present on the software scene, which is presenting crunch mode, working insane hours, in some sort of glamourised way. It is part of the usual storytelling and, and probably, part of the hard work -> ??? -> profit logic.
Let me told you something. When I was starting my career, on my first long term job, we once had a very strong deadline. This made us work in crunch mode for a long time (around 2 months). That meant working around 12 hours or more per day, 6-7 days a week. The very last day (a Sunday), I started working at 9:00 AM and went home the Monday at 6:00 PM, only stopping for eating something quick and going to the toilet. The rest of the team did similarly.
Password Extravaganza: Open discussion about security
In recent times, I’ve been thinking quite a lot about security on Internet. And I mean my personal security on Internet. There has been some recent examples of leaked passwords on some common websites (LinkedIn, I am talking about you!), and I get the impression that the way I was handling passwords on the past was no longer good enough. Luckily, I never had problems, but I thought that I needed review my habits and to take it more seriously.
As with everything that is new, when I open my first email account (about 15 years ago) and register in the very first web pages, my security concerns weren’t really that much important. I started with a relatively (for the time) strong password with more than 6 characters, upper and lower caps + numbers that I can remember easily. Back in the day that was strong enough. I then started to use it everywhere. I’ll call it “password A” from now on.
After some time, I realised that it wasn’t really that good of a strategy, so I got another coupe of stronger passwords, and use them on “sensible” places, like my email, which is the most important point on the chain, or later Facebook.
So, some time ago, I started to think more and more about this, and started being more conscious to password security and the challenges it present. I am going to describe what are my views about passwords and my strategy about them. I am not a security expert, and I think there are a lot of wrong assumptions and myths around passwords. That’s why I want to be open about that, and try to make a “call for review” to share tips and see if I am doing something wrong and see other ways. So, please, add whatever you feel is interesting.
ffind
A sane replacement for command line file search

I tend to use the UNIX command line A LOT. I find it very comfortable to work when I am developing and follow the “Unix as IDE” way. The command line is really rich, and you could probably learn a new different command or parameter each day and still be surprised every day for the rest of your life. But there are some things that sticks and gets done, probably not on the most efficient way.
In my case, is using the command `find` to search for files. 95% of the times I use it, is in this form:
find . -name '*some_text*'
Which means ‘find in this directory and all the subdirectories a file that contains some_text in its filename’
It’s not that bad, but I also use a lot ack, which I think is absolutely awesome. I think is a must know for anyone using Unix command line. It is a replacement for grep as a tool for searching code, and works the following way (again, in my 90% usage)
ack some_text
Which means ‘search in all the files that look like code under this directory and subdirectories that contains the text some_text‘ (some_text can be a regex, but usually you can ignore that part)
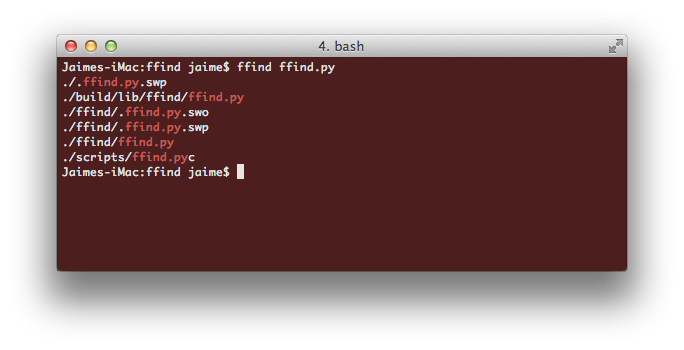
So, after a couple of tests, I decided to make myself my own ack-inspired find replacement, and called it ffind. I’ve been using it for the last couple of days, and it integrates quite well on my workflow (maybe surprisingly, as I’ve done it with that in mind)
Basically it does this
ffind some_text
Which means ‘find in this directory and all the subdirectories a file that contains some_text in its filename’ (some_text can be a regex). It has also a couple of interesting characteristics like it will ignore hidden directories (starting with a dot), but not hidden files, it will skip directories that the user is not allowed to read due permissions and the output will have by default the matching text in color.
The other use case is
ffind /dir some_text
Which means ‘find in the directory ‘/dir’ and all the subdirectories a file that contains some_text in its filename’
There are a couple more params, but they are there to deal with special cases.
It is done in Python, and it is available in GitHub. So, if any of this sounds interesting, go there and feel free to use it! Or change it! Or make suggestions!
ffind in Github

{kind=link}